Fix flaky tests cypress: Stabilize end-to-end tests

Flaky tests in Cypress are the ones that pass one minute and fail the next, with absolutely no changes to your code. It's maddening. These intermittent failures are often triggered by tricky timing issues or inconsistencies in the test environment. The result? Your team's confidence in the entire test suite plummets, and every failure becomes a guessing game: is this a real bug, or just another flaky test?
Why Flaky Tests Silently Sabotage Your Team
It's tempting to brush off a flaky test as a minor nuisance. Just re-run the CI pipeline, and watch it turn green, right? But this seemingly small problem inflicts some serious, silent damage on a development team. The real cost isn't just wasted CI minutes; it's the slow, steady erosion of trust in your tooling.
When tests fail randomly, developers naturally start to ignore them. A red build loses its urgency, creating a culture where genuine bugs can easily slip through the cracks. This "test blindness" grinds development to a halt, as every single failure demands a manual investigation just to figure out if it's legitimate.
The Hidden Costs of Inconsistent Tests
The ripple effect of flaky Cypress tests goes far beyond the code, hitting team morale and messing with project timelines. Each one of these intermittent failures throws a wrench into the development workflow, creating a cascade of negative outcomes:
- Decreased Productivity: Engineers end up burning precious time re-running builds or chasing down phantom issues instead of shipping new features.
- Slower Deployments: When you can't trust your automated quality gates, releases get delayed. The fear of a real bug hiding behind a flaky test is real.
- Accumulated Technical Debt: Ignoring flaky tests is a classic form of technical debt. Over time, it makes the entire test suite fragile and a nightmare to maintain. You can dig deeper into this by checking out our guide on the meaning of flaky tests for developers.
While Cypress is an incredibly powerful tool, it's not immune to this problem. An analysis of over 318 million test records revealed that Cypress has an average flakiness rate of 0.83%, which can balloon to a staggering 4.2% in some projects. It's clear that tackling these flaky test issues head-on is a crucial investment. You can find more insights from the Cypress vs. Playwright flakiness comparison.
The biggest danger of a flaky test is that it normalizes failure. Once your team accepts that tests can fail for "no reason," you've lost the primary benefit of automated testing—confidence.
Diagnosing the Root Causes of Flakiness
To get a handle on flaky tests in Cypress, you have to put on your detective hat. These intermittent failures rarely announce their source. Instead, they leave behind a trail of subtle clues hidden in timing quirks, network requests, and unpredictable DOM behavior. Hunting down these root causes is easily the most critical part of building a stable and trustworthy test suite.
Most of this flakiness isn't truly random. It's usually a symptom of a race condition—a dead heat between your test commands and your application's actual state. Cypress moves incredibly fast, and if your app is still fetching data or running an animation, Cypress might barrel ahead and try to interact with an element that just isn't ready. The result? A failure that mysteriously vanishes on the next run.
The Dominance of Timing Issues
Timing is everything in end-to-end testing, and it’s the number one cause of headaches. In fact, research from the team at Cypress.io revealed that a staggering 37% of test failures are caused directly by timing issues like improper waits and race conditions. This is the classic scenario where a test tries to interact with an element before it's fully loaded or visible.
It's a problem that gets even trickier with modern asynchronous web apps clashing with Cypress's default execution model. This is where a deep understanding of your application's behavior is non-negotiable. For instance, subtle bugs related to managing session expirations and timeouts can pop up as timing-related failures that are notoriously difficult to reproduce on your local machine.
Common Flakiness Triggers and Their Symptoms
Every type of issue leaves a different fingerprint in your test logs and videos. Getting familiar with these signatures helps you quickly narrow down the possibilities and get to the root of the problem faster. It’s a skill you build over time, but you can get a head start by learning about advanced flaky test detection methods.
To help you get started, I've put together a quick reference table that maps common triggers to the symptoms you'll likely see in your Cypress logs.
Common Flakiness Triggers and Their Symptoms
| Root Cause | Common Symptom in Cypress Logs | Example Scenario |
|---|---|---|
| Asynchronous Operations | cy.get(...) failed because it timed out retrying |
Your test tries to click a button, but the API call that enables it hasn't completed yet. |
| Unstable DOM Elements | cy.click() failed because this element is detached from the DOM |
A framework like React re-renders a component, replacing the element your test was about to interact with. |
| Animations & Transitions | cy.click() failed because this element is being covered by another element |
A modal is still fading in, and Cypress tries to click a button on it before the animation is finished. |
Think of these patterns as clues. When you see a "detached from DOM" error, your first thought should be about re-renders, not network speed. This mental map saves a ton of debugging time.
Here are a few of the most common culprits I see in the wild:
- Asynchronous Operations: This is the big one. Your test tries to validate text that hasn't arrived from an API call yet. It fails. On a re-run, the network is a fraction of a second faster, and the test passes. Classic race condition.
- Unstable DOM Elements: Modern frameworks love to re-render the DOM. A test might grab a reference to an element just moments before it gets wiped and replaced, leading to the infamous "detached from DOM" error.
- Animations and Transitions: Cypress might see an element in the DOM, but a CSS transition is still moving it or fading it in. An attempted click fails because another element is technically covering it, or it’s not yet considered "actionable."
Key Takeaway: A flaky test is almost always a sign that your test code is making a wrong assumption about your app's state. The fix isn't to litter your code with arbitrary cy.wait() delays, but to teach your test how to wait for the correct application state before moving on.Actionable Strategies for Eliminating Flaky Tests
Okay, you've pinpointed the likely suspects behind your flaky tests. Now it's time to roll up your sleeves and get practical. Getting rid of flaky Cypress tests isn't about sprinkling cy.wait() everywhere; it’s about fundamentally changing how you write assertions and interact with your application.
The core idea is simple: your test needs to wait for your app to be in a specific, verifiable state before it does anything else. Cypress is built for this, with its automatic retries on most commands. The trick is knowing exactly what to wait for.
This isn't a random whack-a-mole game. A structured approach is key.
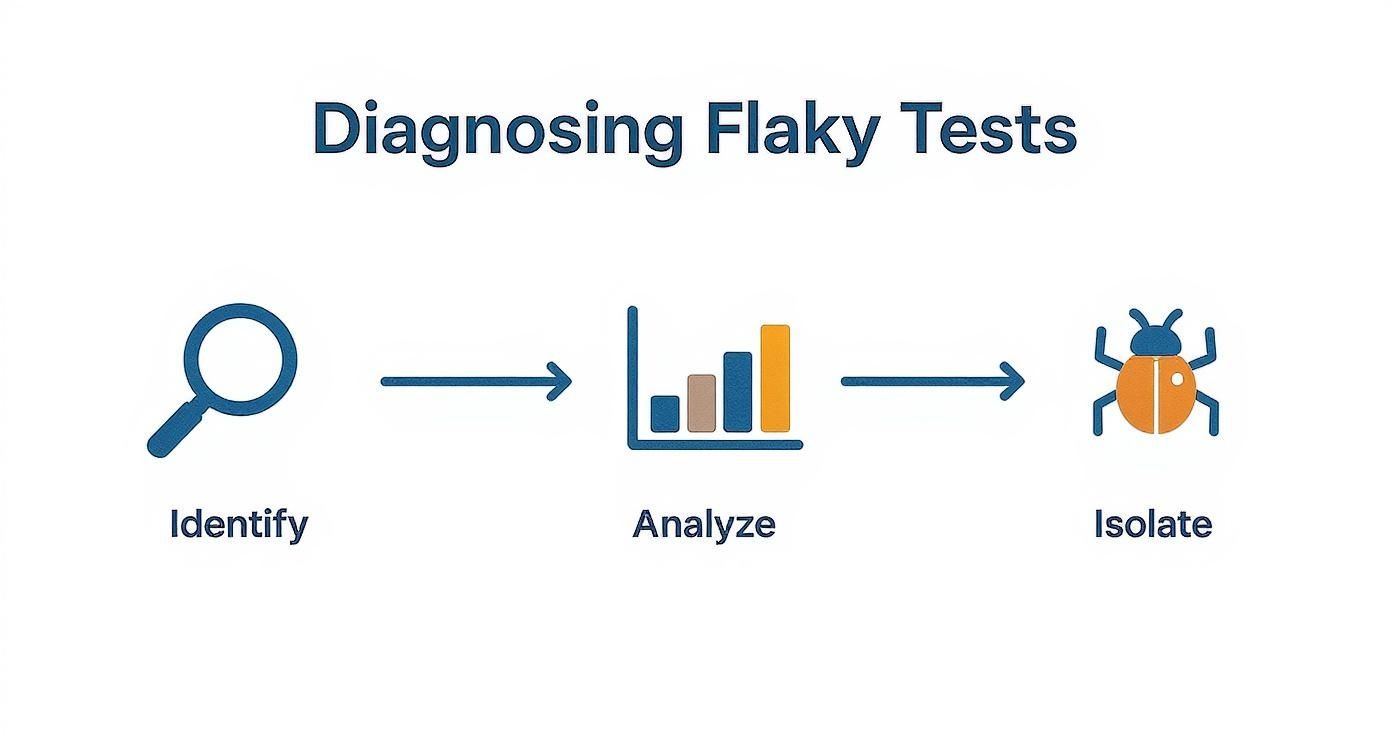
Starting broad and then narrowing down to the root cause before you change a single line of code will save you a world of headaches.
Master Cypress Timing and Assertions
One of the most common mistakes I see teams make is reaching for a quick cy.wait(500). It feels like a fix, but it's just a band-aid. You're just adding a static delay that slows your test suite down and doesn't actually solve the underlying race condition.
A far more robust approach is to lean on Cypress's built-in assertions to wait for the DOM to reflect the state you expect. Instead of guessing how long an action will take, just tell Cypress what the end result should look like.
Before (The Flaky Way):
cy.get('[data-cy="submit-button"]').click();
cy.wait(1000); // Bad practice: hoping the success message appears in time
cy.get('.notification-success').should('contain', 'Profile Updated!');
After (The Stable Way):
cy.get('[data-cy="submit-button"]').click();
// Good practice: Cypress will automatically retry until this element exists
// and contains the text, or until the command times out.
cy.get('.notification-success', { timeout: 10000 })
.should('contain', 'Profile Updated!');
This small change makes a massive difference. The test is no longer a hopeful guess; it's a deterministic check. It will only proceed once that success notification is actually on the page, making it immune to small lags in network or server speed.
Adopt a Bulletproof Selector Strategy
Another huge source of flakiness is brittle selectors. When you tie your tests to CSS classes like .btn-primary or text content like cy.contains('Submit'), you're setting yourself up for failure. These things change all the time for design tweaks or copy updates, breaking tests for reasons that have nothing to do with functionality.
The gold standard here is to use dedicated test attributes.
The most impactful, long-term fix for flaky tests is to decouple them from your application's styling and content. Using data-cy attributes makes your tests resilient to UI refactors and content changes.By adding data-cy or similar attributes directly into your HTML, you create a dedicated hook for your tests that won’t be touched by designers or copywriters.
- Fragile Selector:
cy.get('.styles__button--1AbCd') - Slightly Better:
cy.contains('Save Changes') - Bulletproof Selector:
cy.get('[data-cy="profile-save-button"]')
Yes, this requires getting your development team on board, but the payoff in test stability is enormous. Your tests will finally stop breaking every time a button color is changed.
Isolate Tests by Mocking API Responses
Tests that hit a live backend are at the mercy of network latency, server downtime, and changing data—a perfect recipe for flakiness. Your best friend here is cy.intercept(). This command lets you catch outgoing network requests and feed your test a fake, predictable response instantly. For a deeper look, some great articles explain how to stabilize your test suite by managing flaky Cypress tests.
This tactic ensures your front-end tests are focused only on UI behavior, not on the reliability of your backend.
Example Without Intercept:
// This test depends on the real API being fast and available.
it('shows user data fetched from the server', () => {
cy.visit('/dashboard');
cy.get('[data-cy="user-name"]').should('contain', 'Jane Doe');
});
Example With cy.intercept():
// This test is fast, reliable, and isolated.
it('shows user data from a mock response', () => {
cy.intercept('GET', '/api/user', {
statusCode: 200,
body: { id: 1, name: 'Jane Doe', email: 'jane.doe@example.com' },
}).as('getUser');
cy.visit('/dashboard');
cy.wait('@getUser'); // Explicitly wait for the mock request to complete
cy.get('[data-cy="user-name"]').should('contain', 'Jane Doe');
});
By intercepting the API call, you guarantee the data is always the same and arrives in milliseconds. This completely removes network variability from the equation, making your tests faster and rock-solid.
Fine-Tuning Your Cypress Configuration for Stability
While tracking down and fixing individual flaky tests is a must, some of the most powerful solutions aren't in your test files at all. They're waiting for you in cypress.config.js. By tweaking your global configuration, you can build a much more resilient foundation for your entire test suite, making it far less prone to those frustrating intermittent failures.
This isn't about patching a single test; it's about hardening the entire framework. Think of it like adjusting the suspension on a car for a bumpy road instead of telling the driver to swerve around every single pothole. It's a proactive strategy that pays dividends across all your specs.
Implementing a Smart Retry Strategy
One of the most effective weapons in your arsenal against flakiness is Cypress's built-in test retries feature. When a test fails, you can tell Cypress to automatically run it again a set number of times. This is perfect for catching those fleeting, transient issues—a momentary network blip or a slow-loading animation that likely wouldn't fail a second time.
But how do you set this up without just masking real, consistent bugs? The trick is to treat your local development and your CI pipeline differently.
runMode: This is for when you execute tests withcypress run, which is almost always in your CI/CD environment. Setting this to 2 or 3 gives you a solid safety net for catching genuine flakes during your automated runs.openMode: This applies when you're running tests interactively withcypress openon your own machine. Keeping this at 0 (or maybe 1 at most) is the way to go. If a test fails locally, you want to see that failure immediately so you can debug it, not have it pass on a retry and hide the underlying problem.
Retries are a safety net, not a magic bullet. If a test consistently passes only after a retry, that's a huge red flag. It’s pointing directly at an underlying timing issue or race condition that still needs to be fixed in the test code itself.
Setting this up in your cypress.config.js is super simple:
module.exports = {
retries: {
// Configure retries for cypress run
runMode: 2,
// Configure retries for cypress open
openMode: 0
}
};
This simple configuration strikes the perfect balance, giving you stability in CI without hiding bugs when you're developing locally.
Adjusting Global Command Timeouts
Another powerhouse configuration tweak is adjusting the defaultCommandTimeout. Out of the box, Cypress will wait up to four seconds for commands like cy.get() to find an element before it gives up and fails. For a lot of apps, that’s plenty of time.
But if you're working with an application that has heavy data loads, complex client-side rendering, or slow API responses, this default can easily become a primary source of flaky tests.
Instead of littering your code with individual { timeout: 10000 } overrides, you can set a more generous global default. If you know from experience that your app often takes around six seconds to render key components, increasing the default can wipe out an entire category of flakiness in one go.
module.exports = {
defaultCommandTimeout: 8000, // 8 seconds
// other configurations...
};
Upping this timeout gives your application a little more breathing room. It makes your tests less likely to fail just because a resource took a fraction of a second longer than usual to load. This one-line change can dramatically improve the stability of your test suite, especially in CI environments where performance can be much less predictable.
Building a Workflow That Prevents Flaky Tests
Fixing flaky tests one by one is a reactive game of whack-a-mole. You can do it forever. The real goal is to stop writing them in the first place. This takes a cultural shift—moving from individual heroics to a team-wide workflow that puts test stability front and center from day one.
It’s about weaving best practices into your daily development cycle so that reliable tests become the default, not an afterthought. When everyone on the team shares responsibility for stability, you'll spend a lot less time staring at failed CI pipelines and a lot more time shipping valuable features.
Adopting a Test Atomicity Mindset
The absolute foundation of a solid testing workflow is test atomicity. This principle is simple: every single test must be completely independent and self-contained. It can't depend on the state left over from a previous test, and it can't leave a mess for the next test to clean up.
We've all seen (or written) those long, complex test chains where one test sets up the data for the next one. This is a ticking time bomb for flaky failures. If that first test fails for any reason, it triggers a domino effect, and you’re left trying to untangle a cascade of seemingly unrelated errors.
Instead, each test should have one job and one job only. This makes them far easier to write, debug, and maintain.
- One Action, One Test: A test should verify a single, specific user action or outcome. That's it.
- No Inter-Test Dependencies: Never, ever create a situation where
test Bwill fail iftest Adoesn't run first. - State Reset: The application's state must be reset to a known, clean slate before every single test runs. No exceptions.
Leveraging Hooks for a Clean Slate
So, how do you achieve this clean slate? The key in Cypress is mastering the beforeEach hook. This hook runs before every it block inside a describe block, giving you the perfect, repeatable moment to reset your application's state.
By consistently using beforeEach for setup tasks—like logging in a user, seeding a database with specific data, or mocking API responses—you guarantee every test starts from an identical, predictable baseline. This one practice alone wipes out an entire class of flaky tests caused by state pollution.For instance, don't log in just once in a before hook. Do it in beforeEach. This ensures that even if one test accidentally logs the user out or messes with their profile settings, the very next test starts fresh with a clean, authenticated session.
Proactive Flakiness Detection with Cypress Dashboard
Your CI/CD pipeline is the final gatekeeper, but a tool like the Cypress Dashboard can be your early warning system. It tracks the pass/fail history of every test over time, making it incredibly good at spotting those sneaky patterns of flakiness that you might not notice on a day-to-day basis.
This flips your workflow from being reactive to proactive. Instead of waiting for a flaky test to block a deployment, you can keep an eye on the dashboard for tests that have a high retry count or inconsistent results. Agile teams are increasingly pairing tools like this with AI-enhanced platforms to make their CI/CD pipelines more reliable. While Cypress is great at preventing many types of flakes, the industry is also leaning into self-healing test automation to keep up with rapid development. You can actually read more about how AI is shaping the future of QA automation.
By baking these practices into your team's process—atomic tests, consistent state resets via hooks, and proactive monitoring—you can build a workflow that stops flaky tests before they're ever merged. It's a cultural shift, but one that leads to a far more resilient and trustworthy test suite.
Got Questions About Flaky Cypress Tests?
Even with the best game plan, you're going to run into weird situations when you're deep in the trenches debugging flaky Cypress tests. Let's tackle some of the most common questions that pop up.
Is This Test Flaky or Is It a Real Bug?
This is the big one, right? The tell-tale sign of a flaky test is its sheer unpredictability. If a test fails in your CI pipeline but then passes the moment you re-run it—with zero code changes—you're almost certainly looking at a flake.
A real bug, on the other hand, is reliably broken. It will fail consistently under the same conditions, every single time. The easiest way to get to the bottom of it is to check the test's history in the Cypress Dashboard. A pattern of failures followed by passes on retries is a dead giveaway for flakiness.
Should I Just Crank Up the Default Timeouts?
It's tempting, I know. Bumping up defaultCommandTimeout feels like a quick and easy win, but it usually just slaps a band-aid on a deeper issue. You might be hiding slow API responses or sluggish client-side rendering. It’s a temporary patch, not a real solution.
A far more robust approach is to wait for specific conditions in your application to be met.
- Use
cy.intercept()to pause your test until a critical network request has actually finished. - Lean on assertions like
.should('be.visible')or.should('exist')to ensure DOM elements are ready before you try to interact with them.
This strategy makes your tests more resilient because they're tied to your application's actual state, not just some arbitrary timer.
Key Insight: If you want to make one change that has the biggest impact, focus on your selector strategy. Stop relying on CSS classes or text that might change. Instead, add dedicated test attributes like data-cy='submit-button' to your elements. This decouples your tests from UI tweaks and makes them incredibly more stable over the long haul.At Mergify, we know a rock-solid CI pipeline is the backbone of any great development team. Our platform is built to crush bottlenecks and make sure your code is always ready to ship. Learn how Mergify can streamline your workflow.