8 Best Practice DevOps Strategies for 2025

In the competitive sphere of software development, last year’s successful process can quickly become this year's primary bottleneck. The tools, architectural patterns, and security threats evolve so rapidly that a static approach to development and operations is no longer viable. For this reason, adopting a modern best practice DevOps strategy is not just a competitive advantage; it's a core requirement for building resilient, scalable, and secure software. Elite engineering teams understand this continuous need for refinement and actively rethink their workflows to stay ahead.
This guide is designed to move beyond theoretical discussions and provide a concrete, actionable blueprint. We will dive deep into eight critical practices that high-performing teams are implementing to optimize their entire software development lifecycle. You will gain practical insights into fortifying your CI/CD pipeline, embedding security from the start, and creating a culture where collaboration and automation thrive.
From Infrastructure as Code (IaC) and comprehensive observability to automated testing and robust incident management, each section offers specific implementation details. The goal is straightforward: to equip your team with the knowledge to transform development from a series of disjointed, manual steps into a streamlined, efficient, and predictable flow. These strategies are the foundation for shipping better software, faster, and with greater confidence. By mastering these principles, you can ensure your team is not just keeping up but setting the pace for innovation and reliability.
1. Infrastructure as Code (IaC)
Infrastructure as Code (IaC) is a foundational DevOps practice that involves managing and provisioning computing infrastructure through machine-readable definition files, rather than through manual processes or interactive configuration tools. This approach treats infrastructure configuration as software, allowing you to apply development best practices like version control, code review, and automated testing to your infrastructure management. By defining resources like virtual machines, networks, and load balancers in code, teams achieve consistent, repeatable, and scalable environments.
This shift from manual to automated provisioning is a cornerstone of any effective best practice devops strategy. It eliminates the risk of "configuration drift," where inconsistencies between environments lead to deployment failures and bugs. Instead of an operations team manually clicking through a cloud provider's console, they write code using tools like Terraform, AWS CloudFormation, or Ansible to define the desired state of the infrastructure. This code then serves as the single source of truth, enabling reliable deployments across development, staging, and production.
Key Benefits and Implementation
Adopting IaC delivers significant advantages. For example, Airbnb uses Terraform to manage thousands of services, enabling rapid iteration and reliable infrastructure management at a massive scale. Similarly, Spotify leverages Terraform and Helm to manage its complex Kubernetes deployments, ensuring consistency and speed. The primary benefits include:
- Consistency: Guarantees that every environment is provisioned identically, reducing "it works on my machine" issues.
- Speed and Efficiency: Automates the provisioning process, allowing teams to deploy complex infrastructure in minutes instead of hours or days.
- Version Control: By storing infrastructure definitions in a Git repository, you gain a full audit trail of every change, can easily roll back to previous states, and collaborate effectively through pull requests.
The following infographic provides a quick reference to the core concepts, benefits, and popular tools associated with Infrastructure as Code.
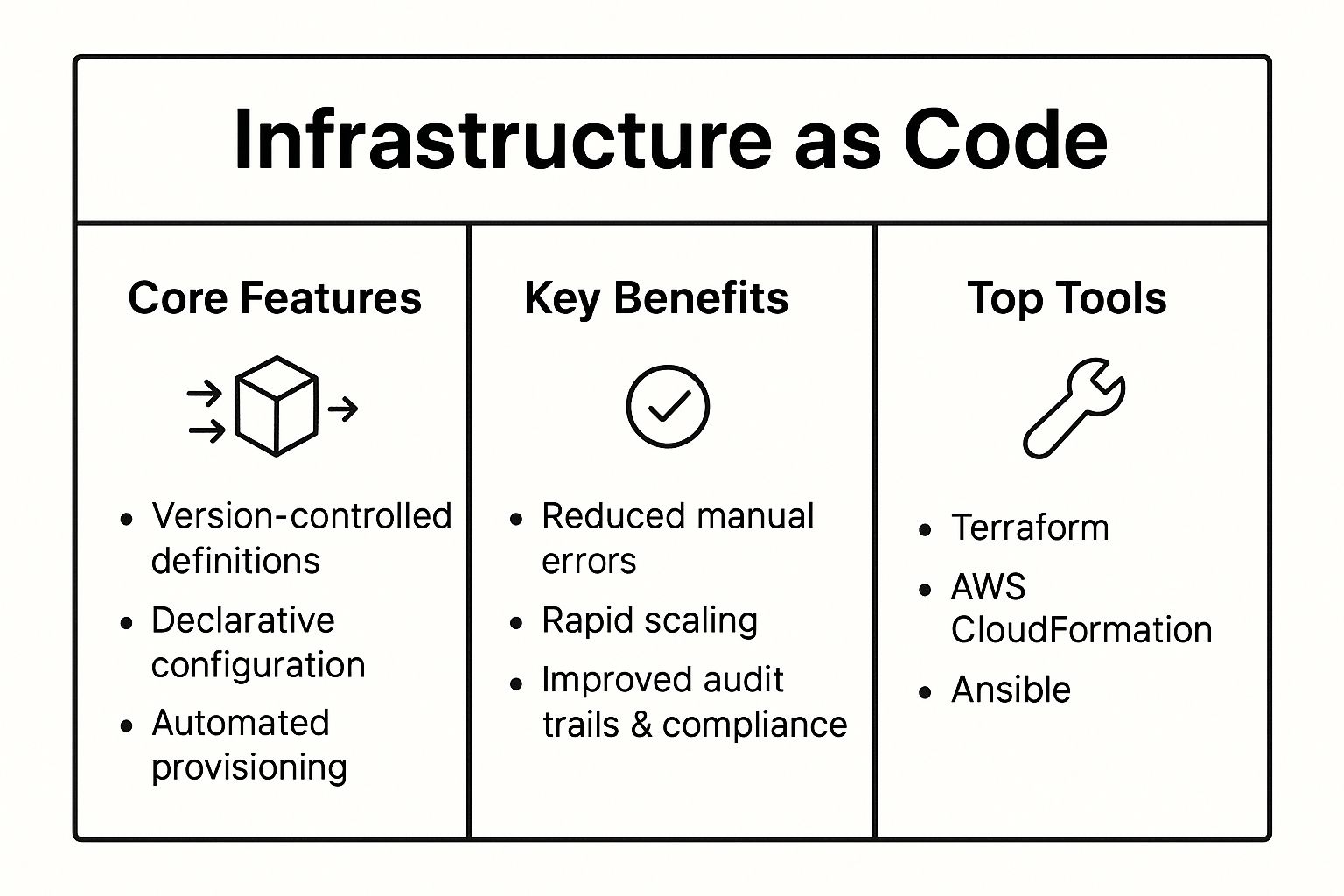
As the summary highlights, the combination of version-controlled, declarative configurations and automated provisioning directly leads to fewer manual errors and improved compliance. For a deeper dive into implementation details and advanced strategies, you can learn more about Infrastructure as Code (IaC) best practices. This structured approach is essential for any organization looking to build a resilient and scalable CI/CD pipeline.
2. Continuous Integration/Continuous Deployment (CI/CD)
Continuous Integration/Continuous Deployment (CI/CD) is the engine of modern DevOps, automating the software release process from code commit to production deployment. CI is the practice of developers frequently merging their code changes into a central repository, after which automated builds and tests are run. CD extends this automation, automatically deploying all code changes that pass the CI stage to a testing or production environment. This automated pipeline ensures that new code is built, tested, and deployed with speed and reliability.
This disciplined automation is a critical component of any best practice devops framework. It bridges the gap between development and operations by creating a fast, reliable, and repeatable process for delivering software. Instead of risky, infrequent "big bang" releases, teams can deliver small, incremental changes. This practice reduces risk, accelerates feedback loops, and allows organizations to respond to market demands with agility. The goal is to make deployments a predictable, low-stress, and routine event.
Key Benefits and Implementation
Implementing a robust CI/CD pipeline delivers transformative results. For instance, Amazon famously averages a deployment every 11.7 seconds, and Etsy performs over 50 deployments per day, all enabled by mature CI/CD practices. This high velocity allows them to innovate rapidly while maintaining system stability. The core benefits include:
- Accelerated Delivery: Automates the entire release process, enabling teams to release new features and bug fixes to customers significantly faster.
- Improved Quality: Integrates automated testing (unit, integration, and end-to-end) into every stage, catching bugs early before they reach production.
- Reduced Risk: Smaller, frequent deployments are less risky than large, monolithic ones. If a problem occurs, it is easier to identify the cause and roll back the change.
- Enhanced Productivity: Frees developers from manual deployment tasks, allowing them to focus on writing code and building features.
A well-structured pipeline is the key to unlocking these benefits. For a practical look at building and optimizing these workflows, you can explore in-depth guides on implementing GitLab CI/CD pipelines. By starting with a simple build-and-test pipeline and progressively adding stages like security scanning, performance testing, and automated deployment, teams can create a powerful and efficient delivery system.
3. Monitoring and Observability
Monitoring and observability are critical DevOps practices focused on collecting, analyzing, and acting on data to understand a system's health, performance, and behavior. While traditional monitoring tracks predefined metrics (like CPU usage and latency), observability provides deeper, more exploratory insights into system internals. This is achieved by analyzing telemetry data from the three pillars: metrics, logs, and traces, which allow teams to ask new questions about system behavior without needing to deploy new code.
This evolution from simple monitoring to comprehensive observability is a vital part of any modern best practice devops approach. It empowers teams to move from reactive problem-solving to proactive performance optimization. Instead of just knowing that an error occurred, observability helps you understand why it occurred by tracing the full lifecycle of a request across distributed services. This granular visibility is essential for debugging complex, microservices-based architectures where failures can have cascading effects.

Key Benefits and Implementation
Adopting robust observability delivers transformative results. For instance, Netflix's chaos engineering principles are built upon a strong observability foundation, allowing them to intentionally break systems to find weaknesses before they impact users. Similarly, Shopify relies on its observability platform to handle the immense traffic spikes of Black Friday, ensuring system stability and optimal customer experience. The primary benefits include:
- Faster Troubleshooting: Enables engineers to quickly pinpoint the root cause of issues in complex, distributed systems, drastically reducing Mean Time to Resolution (MTTR).
- Proactive Performance Tuning: Provides the data needed to identify bottlenecks, optimize resource usage, and improve application performance before users are affected.
- Data-Driven Decision Making: Empowers teams to make informed decisions about feature rollouts, infrastructure scaling, and reliability targets using concrete data from Service Level Indicators (SLIs) and Service Level Objectives (SLOs).
By implementing the three pillars (metrics, logs, and traces) and focusing on business-relevant outcomes, teams can build more resilient and reliable systems. For a more detailed guide on setting up effective tracking systems, you can learn more about the fundamentals of infrastructure monitoring. This comprehensive insight is no longer a luxury but a necessity for operating modern applications at scale.
4. Automated Testing Strategy
An Automated Testing Strategy is a comprehensive plan for integrating various types of automated tests throughout the software delivery lifecycle. Rather than treating testing as a separate phase, this approach embeds quality checks directly into the development workflow. It includes a mix of unit, integration, end-to-end (E2E), and performance tests that are automatically triggered within the CI/CD pipeline, providing rapid feedback on code changes and preventing regressions from reaching production.
This methodical approach to quality assurance is a critical component of any modern best practice devops framework. It transforms testing from a manual bottleneck into an automated, continuous process that supports speed and stability. Instead of relying solely on a QA team to manually verify features before a release, developers write tests alongside their code. These tests are then executed automatically with every commit, ensuring that new features work as expected and do not break existing functionality. This immediate feedback loop allows teams to catch and fix bugs early when they are least expensive to resolve.
Key Benefits and Implementation
Adopting a robust automated testing strategy is a hallmark of high-performing engineering organizations. For instance, Microsoft famously runs over 60,000 automated tests on every new build of its Windows operating system to ensure stability at an immense scale. Similarly, Spotify utilizes contract testing to verify the interactions between its many microservices, preventing integration failures without the overhead of full end-to-end test suites. The primary benefits include:
- Improved Code Quality: Catches bugs and regressions early in the development cycle, leading to a more stable and reliable product.
- Increased Velocity: Frees up developers and QA engineers from repetitive manual testing, allowing them to focus on building new features and improving the product.
- Faster Feedback Loops: Provides immediate feedback on code changes, enabling developers to identify and fix issues in minutes rather than days.
As pioneers like Kent Beck and Martin Fowler have emphasized, a structured approach like the "testing pyramid" (many unit tests, fewer integration tests, and even fewer E2E tests) is essential. For a deeper understanding of how to build and maintain an effective test suite, you can explore the concepts detailed on the Google Testing Blog. By making automated testing an integral part of the development process, teams can confidently release high-quality software at a rapid pace.
5. Configuration Management
Configuration Management (CM) is a systematic process for maintaining computer systems, servers, and software in a known, consistent state. It involves defining a desired state for your application's configuration and then using automation to ensure all systems conform to it. This practice treats configuration files as code, allowing you to version control, test, and review changes just like any other software artifact, which is a key component of a best practice devops approach.
This discipline is crucial for eliminating "configuration drift," a common problem where servers in the same environment become subtly different over time due to manual updates and ad-hoc changes. Instead of manually logging into servers to tweak settings, teams use tools like Ansible, Puppet, or Chef to write declarative or procedural "recipes" that define everything from installed software packages to user permissions and network settings. This ensures that every server, from development to production, is a perfect, predictable replica.
Key Benefits and Implementation
Adopting Configuration Management is essential for achieving stability and predictability at scale. For instance, Facebook famously uses Chef to manage its massive and complex infrastructure, while Puppet is trusted to manage millions of nodes across various global enterprises. The primary benefits include:
- Consistency and Reliability: Enforces a uniform configuration across all environments, drastically reducing bugs and deployment failures caused by environment-specific inconsistencies.
- Automation and Efficiency: Automates repetitive and error-prone manual tasks, freeing up engineers to focus on more strategic work and enabling rapid scaling of infrastructure.
- Security and Compliance: Provides a clear, auditable trail of all configuration changes. It allows teams to enforce security policies systematically and quickly patch vulnerabilities across the entire fleet.
To implement CM effectively, teams should treat configuration as code by storing it in a version control system like Git. It's also critical to use encrypted storage for secrets and sensitive data, implement robust validation and testing for configuration changes before deployment, and clearly document all dependencies. By planning for rollback scenarios, you can ensure that any problematic changes can be reverted quickly, maintaining system integrity.
6. Collaboration and Communication
Collaboration and communication are the cultural glue of DevOps, focusing on breaking down the traditional silos between development, operations, and other business stakeholders. This practice involves establishing shared tools, transparent processes, and a culture that fosters open dialogue. Instead of teams operating in isolation, they are integrated into cross-functional units that share responsibility for the entire software delivery lifecycle, from conception to production support. This holistic approach ensures everyone is aligned on common goals and can respond to changes rapidly.
This cultural shift is a critical component of any successful best practice devops implementation. It replaces blame-oriented post-mortems with blameless retrospectives and prioritizes synchronous and asynchronous communication channels that provide visibility to all. By implementing practices like ChatOps, shared monitoring dashboards, and structured incident response protocols, organizations create an environment where information flows freely, enabling faster problem-solving and continuous improvement. This is about embedding communication into the workflow, not treating it as an afterthought.
Key Benefits and Implementation
Adopting a collaborative culture yields powerful results. For instance, Spotify's famous squad model creates autonomous, cross-functional teams that own features end-to-end, fostering innovation and rapid delivery. Similarly, GitHub's remote-first culture is built on a foundation of asynchronous communication and documentation, proving that effective collaboration isn't tied to physical proximity. The primary benefits include:
- Accelerated Problem Solving: When developers, operations, and security experts share context and tools, they can diagnose and resolve incidents much faster.
- Reduced Silos and Friction: Shared ownership and transparent communication dismantle the "us vs. them" mentality, leading to smoother handoffs and fewer bottlenecks.
- Enhanced Innovation: A culture of psychological safety where ideas can be shared freely encourages experimentation and leads to better products and processes.
For organizations looking to foster this environment, the focus should be on creating shared spaces and rituals. You can learn more about building these cultural foundations by exploring the principles outlined in seminal works like Gene Kim's The Phoenix Project. Implementing clear communication protocols and collaborative tooling is the first step toward building a high-performing, integrated team.
7. Security Integration (DevSecOps)
Security Integration, commonly known as DevSecOps, is the practice of embedding security into every stage of the software development lifecycle. Instead of treating security as a final gate or an afterthought, this approach automates and integrates security controls, testing, and monitoring directly into the CI/CD pipeline. The goal is to make security a shared responsibility among development, security, and operations teams, enabling the early detection and remediation of vulnerabilities without sacrificing development speed.
This cultural and technical shift is a critical component of any modern best practice devops strategy. It moves security from a potential bottleneck to an enabler of fast, secure deployments. Teams practice "shifting left," which means addressing security concerns as early as possible in the development process, such as during coding and design phases. By using automated tools for static and dynamic analysis, dependency scanning, and compliance checks within the pipeline, organizations can build security in, rather than bolting it on at the end.
Key Benefits and Implementation
Adopting a DevSecOps mindset transforms how organizations manage risk while accelerating innovation. For instance, Capital One integrated security automation into its DevOps pipelines to ensure continuous compliance and threat detection across thousands of applications. Similarly, Netflix developed a suite of automated security tools that run continuously, allowing its engineers to innovate quickly while maintaining a strong security posture. The primary benefits include:
- Early Vulnerability Detection: Identifies and fixes security flaws early in the development cycle, when they are cheaper and easier to resolve.
- Increased Speed and Agility: Automates security checks within the CI/CD pipeline, eliminating manual security reviews that slow down releases.
- Shared Responsibility: Fosters a culture where everyone, from developers to operations staff, is accountable for security, improving overall vigilance.
Implementing DevSecOps involves integrating security-focused tools and processes at key stages of the pipeline. Starting with automated dependency scanning in your build process can provide immediate value by flagging known vulnerabilities in third-party libraries. Progressing to Static Application Security Testing (SAST) and Dynamic Application Security Testing (DAST) tools within your pipeline automates code analysis and runtime testing. This ensures that security is a continuous, automated, and integral part of your development workflow.
8. Incident Management and Recovery
Incident Management and Recovery is a systematic approach to identifying, managing, and resolving IT service disruptions as quickly as possible. This practice is not just about fixing what’s broken; it's a comprehensive process for detecting, responding to, and learning from system incidents to minimize business impact and prevent recurrence. It treats every outage or degradation as an opportunity to improve system resilience, making it an essential component of any high-performing best practice devops culture. By establishing clear protocols and feedback loops, teams can reduce Mean Time to Recovery (MTTR) and strengthen system reliability over time.
This structured process moves organizations from a reactive, chaotic "firefighting" mode to a proactive and organized response. Instead of ad-hoc troubleshooting, teams follow predefined runbooks and escalation paths to diagnose and mitigate issues efficiently. Core to this philosophy is the blameless post-mortem, a concept popularized by engineers at Etsy and Google. This practice shifts the focus from individual error to systemic flaws, fostering a psychologically safe environment where engineers can openly analyze failures and identify root causes without fear of punishment. This learning-oriented approach is critical for building robust and antifragile systems.
Key Benefits and Implementation
Adopting a formal incident management framework provides transformative benefits. For instance, Google's Site Reliability Engineering (SRE) teams use a sophisticated incident management framework to maintain the high availability of services like Search and Gmail. Similarly, GitHub's transparent public incident reports demonstrate a commitment to learning and customer trust, turning potentially negative events into opportunities to showcase reliability. Key benefits include:
- Faster Recovery: Clear on-call rotations, runbooks, and escalation procedures drastically reduce the time it takes to restore service.
- Reduced Burnout: Tiered on-call schedules and well-defined roles prevent the same engineers from being constantly overwhelmed, promoting a sustainable work-life balance.
- Continuous Improvement: Blameless post-mortems and incident analysis provide actionable insights that directly inform improvements to code, infrastructure, and processes.
For a deeper look into creating a culture that learns from failure, a valuable resource is the collection of insights on Blameless PostMortems. By implementing structured incident response drills, often called "game days," teams can practice their procedures and identify weaknesses before a real incident occurs, ensuring they are prepared to handle any disruption. This proactive stance on failure is what distinguishes elite DevOps organizations.
Best Practices DevOps 8-Point Comparison
| Practice / Aspect | Implementation Complexity 🔄 | Resource Requirements ⚡ | Expected Outcomes 📊 | Ideal Use Cases 💡 | Key Advantages ⭐ |
|---|---|---|---|---|---|
| Infrastructure as Code (IaC) | Medium to High – requires learning new tools and languages, initial setup complex | Moderate – needs tooling, state management, and integration with CI/CD | Consistent, repeatable infra deployments, reduced manual errors | Managing scalable infrastructure, multi-cloud deployments | Version control, rapid scaling, audit trails |
| CI/CD | High – initial pipeline setup and test coverage crucial | Moderate to High – automated build, test, deploy infrastructure | Faster time to market, higher deployment frequency, improved code quality | Frequent releases, rapid feature delivery | Early bug detection, automated testing, rapid feedback |
| Monitoring and Observability | Medium – set up metrics, logs, traces, alerts, complex correlation | High – storage, processing power, and analysis tools | Faster issue resolution, proactive incident detection, performance insights | Production environments, complex distributed systems | Data-driven optimization, improved reliability |
| Automated Testing Strategy | High – significant upfront investment in test creation and maintenance | High – test infrastructure, parallel execution, test data management | Early bug detection, confidence in code changes, reduce manual testing | Continuous deployment, high-quality software delivery | Bug catching, regression prevention, living docs |
| Configuration Management | Medium – learning CM tools, secret handling complexity | Moderate – centralized config storage and secret management | Eliminates drift, consistent environments, rapid provisioning | Environment consistency, secret and config management | Reduced errors, compliance, security improvement |
| Collaboration and Communication | Medium – significant cultural change and communication overhead | Low to Moderate – depending on tools and practices adopted | Faster problem resolution, better alignment, enhanced innovation | Cross-team projects, organizations improving DevOps culture | Shared ownership, accountability, knowledge sharing |
| Security Integration (DevSecOps) | High – complex toolchain integration, requires security expertise | Moderate to High – automated security testing and scanning infrastructure | Early vulnerability detection, compliance, reduced security delays | Security-critical projects, regulated industries | Lower fix cost, shared security responsibility |
| Incident Management and Recovery | Medium – requires procedures, on-call rotation, post-mortems | Moderate – alerting tools, incident management platforms | Reduced downtime, faster recovery, continuous learning | High availability systems, production incident handling | Blameless culture, systematic learning, communication |
From Practice to Performance: Your Next Steps in DevOps
Embarking on a DevOps transformation is a marathon, not a sprint. We have journeyed through eight foundational pillars, from the deterministic power of Infrastructure as Code (IaC) to the resilient framework of Incident Management. Each of these represents a crucial component in building a high-velocity, reliable, and secure software delivery lifecycle. Merely understanding these concepts is the first step; the real value emerges from their consistent application and integration into your team's daily DNA.
Adopting even one of these practices, such as a robust Automated Testing Strategy, can dramatically reduce bugs and increase deployment confidence. Integrating CI/CD pipelines eliminates manual toil and accelerates feedback loops, allowing your developers to focus on innovation rather than tedious release processes. The goal is not perfection overnight, but progressive, measurable improvement.
Synthesizing Your DevOps Strategy
The true power of these best practice DevOps principles is realized when they are woven together into a cohesive strategy. Think of them as interconnected gears in a finely tuned engine:
- IaC and Configuration Management work in tandem to create stable, repeatable environments.
- CI/CD pipelines are the engine, but they are fueled by effective Collaboration and Communication.
- Monitoring and Observability act as the dashboard, providing the critical data needed to steer the engine and prevent breakdowns.
- DevSecOps ensures that security is not a roadblock but a guardrail, integrated throughout the entire process.
This synergy creates a virtuous cycle. Better observability leads to faster incident recovery. Comprehensive automated testing makes CI/CD more reliable. A strong collaborative culture ensures that all these technical practices are adopted effectively, breaking down silos and fostering shared ownership. The ultimate objective is to create a system where quality, speed, and stability are not competing priorities but are instead mutually reinforcing outcomes.
Your Actionable Roadmap Forward
Transforming theory into tangible results requires a deliberate and iterative approach. Avoid the temptation to overhaul everything at once. Instead, identify the area with the most significant friction in your current workflow and start there.
Here is a practical, step-by-step plan to begin your journey:
- Assess and Identify: Conduct a value stream mapping exercise. Pinpoint your biggest bottleneck. Is it flaky tests? Manual deployment processes? A chaotic on-call rotation?
- Select a Pilot Project: Choose a single, low-risk service or application to be your testing ground. This minimizes the blast radius of any initial mistakes and allows the team to learn in a controlled environment.
- Define Success Metrics: Before you begin, establish clear key performance indicators (KPIs). This could be reducing lead time for changes, decreasing the change failure rate, or improving the mean time to recovery (MTTR).
- Implement and Iterate: Focus on implementing one or two of the best practices discussed. For example, containerize the application and define its infrastructure using Terraform (IaC). Then, build a basic CI/CD pipeline to automate its deployment.
- Measure and Evangelize: Track your KPIs and share the results. Demonstrating a tangible win, such as a 50% reduction in deployment time for the pilot project, is the most powerful way to build momentum and gain buy-in for broader adoption.
This iterative approach transforms the daunting task of "adopting DevOps" into a series of manageable, impactful steps. By mastering these best practice DevOps concepts, you are not just optimizing a workflow; you are building a resilient, adaptable, and innovative engineering culture capable of delivering exceptional value to your users.
Ready to eliminate merge conflicts and supercharge your CI/CD pipeline? Mergify automates the most frustrating parts of code integration with its powerful Merge Queue and provides deep CI Insights, helping you implement best practice DevOps with less effort. Discover how you can ship faster and more reliably at Mergify.