A Practical Guide to Fixing Cypress Flaky Tests


You've seen it before. That one Cypress test that passes on your local machine, passes again after a push, and then... fails in CI. You rerun the job. It passes. What gives?
This is a classic flaky test. It's a test that flips between passing and failing without any changes to your code, and it's one of the most frustrating problems in modern development. These aren't just minor annoyances; they're insidious bugs that create chaos in your CI pipeline, eroding trust, killing productivity, and hiding real regressions. Tackling them needs to be a top priority.
The True Cost of Unreliable Cypress Tests
That one random failure does more damage than you think. It's a silent productivity killer. So many teams fall into the "rerun and hope" trap, kicking off the CI job again and crossing their fingers for a green checkmark. This habit doesn't just mask the underlying issues—it slowly breeds a culture where unreliability is considered normal.
Before long, developers stop trusting the test suite entirely. A red build, which should be an all-hands-on-deck alarm signaling a real bug, just becomes background noise. This is where things get dangerous. Developers start merging pull requests despite a failing pipeline, shrugging it off with, "Oh, it's just the flaky login test again."
Beyond Reruns and Delays
The fallout from flaky Cypress tests spreads far beyond a messy CI/CD pipeline. It injects a ton of friction right into your development workflow.
- Delayed Deployments: Hotfixes and critical features get stuck in limbo, waiting for that elusive all-green test run. This creates bottlenecks and stalls the delivery of value to your users.
- Wasted Engineering Hours: Your team ends up burning precious time chasing ghosts. Instead of building features or fixing actual bugs, they’re investigating test failures that turn out to be false alarms.
- Hidden Regressions: Worst of all, a genuine, show-stopping bug could be dismissed as "just another flake," letting it slip right into production.
Treat a flaky test with the same urgency as a production bug. It breaks the fundamental promise of your CI pipeline: to provide a trustworthy signal about the health of your application.
Flaky tests are more common than you might think. A comprehensive study that crunched the numbers on over 318 million test records found that Cypress tests have an average flakiness rate of 0.83%. While that might not sound like a lot, the 99th percentile (P99) for flakiness jumps to a staggering 4.2%. For some projects, that means significant, daily instability. You can dive deeper into the full research on Cypress test flakiness to see the data for yourself.
To give you a clearer picture, here's how these flaky symptoms often get misinterpreted and what they're actually costing you.
Common Flaky Test Symptoms and Their Real Impact
| Symptom | Common Misconception | Actual Impact |
|---|---|---|
| Random CI failures on a single test | "It's a one-off glitch. Just rerun it." | Erodes trust in the CI pipeline; developers start ignoring red builds. |
| Tests failing only in CI, but not locally | "It's probably just a slow CI runner." | Masks genuine race conditions or environment-specific bugs. |
| A test that fails, then passes after a retry | "The retry fixed it. We're good." | Hides the root cause, leading to bigger, harder-to-debug failures later. |
| "That test fails all the time" | "We should just disable it for now." | A critical regression could be missed entirely, shipping a broken feature. |
Seeing the problem laid out like this makes it clear: ignoring flakes isn't an option. The first step toward a resilient automation pipeline is framing the issue correctly—as a high-priority bug that needs to be fixed, not ignored.
Diagnosing the Root Causes of Flakiness
Alright, to actually fix a flaky Cypress test, you have to put on your detective hat. These random failures are almost never truly random. They're symptoms of a deeper, underlying issue. Simply re-running the CI pipeline until it goes green is like putting a piece of tape over your car's check engine light—you're ignoring a problem that’s bound to get worse.
Becoming a good diagnostician means looking past the surface-level failure and hunting for patterns in the chaos. Does the test only fail around 3 p.m.? Does it only break when running alongside another specific test file? These little clues are your breadcrumbs, leading you to the real culprits.
Uncovering Timing and Race Conditions
More often than not, the root of flakiness is a simple mismatch between how fast your test runs and how fast your application is ready. Modern web apps are a whirlwind of asynchronous activity—data fetching, animations kicking in, third-party scripts loading, you name it. Your test script might be barreling ahead, trying to click a button that hasn't even been rendered yet.
This is a massive issue for tests that depend on network requests. A survey from Cypress.io actually highlighted that timing is a huge factor, revealing that a staggering 37% of test failures come from improper waits where elements just aren't available for the test to grab.
A race condition is exactly what it sounds like: your test and your application are "racing" to a finish line, and sometimes, the test just loses. The goal isn't to just slap a longer cy.wait() on it, but to teach the test to be smart enough to know exactly when the application is ready.Analyzing Logs and Test Artifacts
Your first line of defense is the treasure trove of evidence Cypress automatically collects for you. Every single test run, especially in CI, generates artifacts that are pure gold for debugging:
- Videos: Don't just look at the logs; watch the movie. A full recording of the test run shows you exactly what the browser was doing when things went south. You might spot an unexpected pop-up, a slow-loading component, or some other visual quirk you’d never catch otherwise.
- Screenshots: Cypress is smart enough to snap a picture the very instant a test command fails. This single screenshot is often all you need to see the state of the DOM and understand why it couldn't find that element.
It's one thing to have these artifacts, but it's another to use them effectively. When I find a tricky bug, I'll often use an online screenshot editor to annotate what went wrong before sharing it with the team. When you combine these visuals with the detailed runner logs, you get a complete story of the failure. For a deeper look at this process, check out this developer's guide to flaky test detection and prevention.
When a test fails, this simple decision tree can help you decide what to do next.
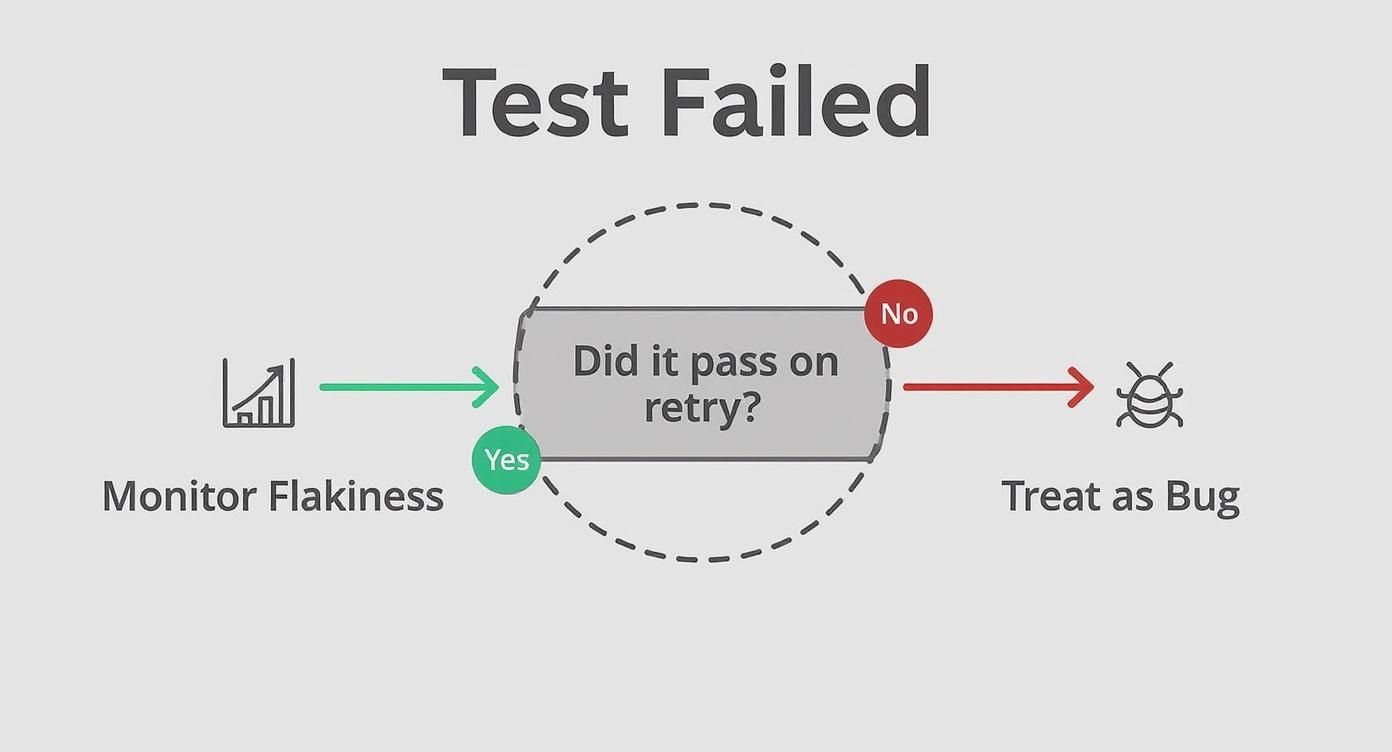
The key here is learning to tell the difference between a random network hiccup and a consistent, repeatable failure. If a test fails even after a retry, it's not "flaky" anymore—it's a legitimate bug that needs to be fixed.
Mastering Cypress Waits and Assertions
A massive source of flaky Cypress tests comes from a fundamental misunderstanding of how Cypress thinks. It's an easy trap to fall into, especially if you're coming from a framework like Selenium where you're used to manually peppering in pauses and sleeps to let the UI catch up.
That old instinct leads directly to the number one anti-pattern in Cypress: cy.wait(500).
This command forces your test to just… stop. It does nothing for a fixed amount of time. While that might patch a failing test on your speedy local machine, it's a ticking time bomb in a CI environment where network speeds and server loads are all over the place. If the app is a bit slow, the wait isn't long enough, and the test fails. If the app is faster, you've just wasted precious seconds, bloating your entire test suite's runtime.
The real solution is to stop telling Cypress how long to wait and instead tell it what to wait for. This simple shift in mindset is the core philosophy behind Cypress's incredible automatic waiting and retry-ability.
Let Cypress Handle the Waiting
Instead of shoving in an arbitrary pause, just chain an assertion directly onto an action or element selector. Cypress is purpose-built to automatically retry the previous command until that assertion passes or its timeout is reached—which by default is a generous 4 seconds.
Think about this classic flaky scenario: you click a button, and a new element is supposed to appear.
- The Anti-Pattern (Flaky):
cy.get('.submit-button').click(); cy.wait(1000); cy.get('.success-message').should('be.visible'); - The Cypress Way (Robust):
cy.get('.submit-button').click(); cy.get('.success-message').should('be.visible');
In that second, robust example, Cypress clicks the button and then immediately starts looking for .success-message. It will keep trying to find that element and confirm it's visible for up to four full seconds before it even thinks about failing. This is so much more resilient because it adapts to your application's actual response time. This approach is a cornerstone of reliable automated GUI tests, making sure your tests are always perfectly synchronized with the application's state.
Key Takeaway: Your assertions are your waits. Every.should()acts as an intelligent, adaptive waiting mechanism that will make your tests dramatically more stable than any fixedcy.wait().
Waiting on Network Requests and Animations
Of course, sometimes the UI's readiness depends on things happening in the background, like an API call finishing up or a CSS animation completing. Hard-coded waits are especially tempting here, but Cypress gives you much smarter tools for these exact situations.
Waiting for APIs with cy.intercept()
When a user clicks something that triggers a network request, the most bulletproof way to wait is to listen for that specific request to complete.
- Intercept the Request: First, use
cy.intercept()to tell Cypress to watch for a specific API call. Give it a handy alias. - Trigger the Action: Next, perform the click or other interaction that fires off the request.
- Wait for the Alias: Finally, use
cy.wait('@yourAlias')to explicitly pause the test until that specific network request has finished.
This method completely eliminates race conditions between your test and the backend. It guarantees your test only proceeds after the necessary data has been fetched and the app has had a chance to render it.
Handling UI Animations
Animations are another common culprit. They can easily cause flakiness if your test tries to interact with an element before its transition is complete. Don't guess with a wait—just assert on the final state.
- Check for a CSS class that gets added or removed at the end of the animation.
- Assert that an element is no longer disabled.
- Confirm that a loading spinner
should('not.exist').
By mastering these assertion-based waiting strategies, you'll shift from writing brittle, time-sensitive tests to creating a robust suite that truly reflects how a real user interacts with your application—patiently waiting for it to be ready before taking the next step.
Isolating Tests for Predictable Outcomes
One of the sneakiest ways flaky tests creep into your Cypress suite is through dependency. It’s a classic trap: one test’s outcome relies on the state left behind by a previous test. Suddenly, you've built a fragile house of cards.
A single failure in that chain can set off a cascade of seemingly unrelated errors, making it a nightmare to track down the original problem.
The bedrock principle for rock-solid stability is test isolation. Each test—every single it block—should be its own self-contained universe. It needs to run on its own, in any order, without messing with its neighbors. It must create its own conditions, perform its actions, and then clean up after itself, leaving the environment pristine for whatever runs next.
Creating a Clean Slate Before Every Test
Cypress gives us the perfect tool for this: the beforeEach() hook. This block of code runs before every single test within a describe block, giving you a reliable moment to reset the application state. It’s the ideal place to guarantee each test starts from an identical, predictable baseline.
Think of a typical beforeEach() hook as your recipe for cleanliness. You can systematically wipe the slate clean, preventing data from one test from "leaking" into the next and causing all sorts of weird behavior.
A robust reset process almost always includes:
- Clearing Cookies:
cy.clearCookies()gets rid of any session cookies or tracking data that could throw off authentication or the UI state. - Wiping Local Storage: Running
cy.clearLocalStorage()purges any persisted data the application might be relying on between visits. - Resetting Session Data: If your app uses session storage,
cy.window().then((win) => win.sessionStorage.clear())makes sure it’s empty.
This cleanup routine is non-negotiable. I've seen it countless times: failing to reset the environment is a top reason why tests pass locally but blow up in CI, where the execution order can be completely different.
By resetting the application's state before each test, you transform your test suite from a sequential, fragile script into a collection of independent, resilient validation units.
Managing Test Data and Programmatic Logins
Beyond clearing storage, true isolation means controlling your data and user state. Trusting a pre-existing user in a shared test database is just asking for trouble. What happens when another test deletes that user? Or changes their password? Your test will fail for reasons that have absolutely nothing to do with the feature you're actually testing.
The only reliable way forward is to create the exact state you need, programmatically.
- Programmatic Logins: Stop logging in through the UI in every test. It’s painfully slow and brittle. Instead, create a custom command like
cy.login()that sends acy.request()directly to your authentication endpoint to set a session cookie. This is thousands of times faster and far more reliable. - Database Seeding: For tests that require specific data, use tasks or API calls to seed the database with the exact records you need right before the test runs. This ensures the data is always there and in the state you expect.
Adopting these habits is central to effective test environment management best practices, because it severs the external dependencies that breed flakiness. When you make each test responsible for its own setup and cleanup, you build a Cypress suite that’s not just more stable, but also way easier to debug and maintain.
Once you’ve nailed down waits and mastered test isolation, you’re ready to climb to the next level of stability. This is where you graduate from fixing common flaky test issues to proactively engineering your tests to be immune to entire categories of problems.
The secret? Gaining absolute control over the most chaotic part of any test run: the network.
Even a perfectly written test can be brought to its knees by a slow or failing backend API. This is a classic CI killer. The most seasoned Cypress users tackle this head-on by completely taking charge of the network layer. For this, cy.intercept() is about to become your new best friend.
Gaining Full Control with Network Mocking
Instead of just waiting for real API calls to complete, what if you could just tell your application what the response should be? That's exactly what cy.intercept() allows you to do. You can catch outgoing requests and feed your app a predictable, static response every single time.
This technique, often called stubbing or mocking, makes your test completely independent of the backend. Is the API down for maintenance? Doesn't matter. Is it running slow today? Your tests won't even notice.
Let's say you're testing a user dashboard that pulls data from an endpoint like /api/dashboard. If that endpoint is down, your test fails—even if the frontend code is flawless. By mocking the response, you guarantee your test environment is always in the exact state you need it to be.
it('displays the correct dashboard widgets with mocked data', () => {
// Intercept the API call and provide a static JSON response from a fixture file
cy.intercept('GET', '/api/dashboard', { fixture: 'dashboard-data.json' }).as('getDashboardData');
cy.visit('/dashboard');
// The test now uses your fixture data, not the live API
cy.wait('@getDashboardData');
cy.get('.widget-sales').should('contain', '$50,000'); // This value comes from your fixture file
});
Not only does this eliminate a huge source of network-related flakiness, but it also makes your test suite run dramatically faster. You're no longer at the mercy of real server response times. One of the most effective ways to handle cypress flaky tests is to use cy.intercept() to mock API responses, decoupling your tests from unpredictable network conditions. You can find more insights about test isolation on katalon.com.
Creating Reusable and Stable Interactions
As your test suite expands, you'll start to see the same patterns crop up again and again. Maybe it’s a complex login flow or navigating a multi-step onboarding modal. A real pro-level move is to wrap these repetitive actions into Cypress Custom Commands.
This is a game-changer for both stability and maintainability.
Instead of copy-pasting the same ten cy.get() and .click() commands across dozens of tests, you can create a single, rock-solid command like cy.completeOnboardingModal().
This pays off in two huge ways:
- Centralized Logic: If the modal's UI ever changes, you only have to update the custom command in one place, not hunt it down in twenty different test files.
- Built-in Stability: You can build your assertions and waits directly into the command itself. This ensures every step is confirmed and solid before the next one even thinks about running.
By creating custom commands, you're essentially building a stable, internal API for your application's UI. This makes your tests cleaner, more readable, and far less brittle when future changes come along.
To reach that ultimate level of stability, these test-level fixes should be part of your team's wider, comprehensive software quality assurance processes.
Finally, don't overlook the intelligence built into the Cypress Dashboard. It’s more than just a place to see results; it’s a tool for observability. It automatically tracks your test history, smartly flagging tests that fail and then pass on a retry. This data is pure gold for pinpointing your most troublesome tests over time, allowing you to focus your efforts where they'll have the biggest impact.
Got Questions? We've Got Answers
When you're deep in the world of test automation, questions are bound to pop up, especially when you're wrestling with something as frustrating as flaky tests. Here are a few quick answers to the common curveballs we see developers facing with unpredictable Cypress behavior.
How Can I Automatically Retry a Failing Cypress Test?
Cypress has a fantastic built-in test retries feature that's perfect for handling those once-in-a-blue-moon issues. You can switch it on right in your cypress.config.js file by setting the retries option.
For instance, { retries: { runMode: 2 } } tells Cypress to automatically give any failing test up to two more shots, but only when running in runMode—like in your CI environment.
Think of this as a safety net for occasional network hiccups or a slow CI runner. It's a great temporary bandage, but it's not a permanent solution. Over-relying on retries can hide deeper, more sinister problems, so always make it a priority to dig in and find the real root cause of the flakiness.
What's the Best Way to Debug a Test That Only Fails in CI?
When a test passes on your machine but throws a fit in your CI pipeline, the artifacts Cypress generates are your best friends. Videos and screenshots are your first line of defense, giving you a frame-by-frame replay of exactly what went wrong.
This is where the Cypress Dashboard really shines. It neatly records and organizes all these artifacts for every single run, making diagnosis much easier. If the visuals don't tell the whole story, it's time to get more granular. Sprinkle some cy.log() commands into your test code to output application state, API responses, or critical variable values at key moments. This will help you spot what's different in the CI environment versus your local setup.
Should I Ever Use a Fixed cy.wait() Command?
Almost never. Seriously. A hard-coded wait like cy.wait(1000) is a massive anti-pattern and one of the biggest culprits behind both flaky Cypress tests and painfully slow test suites. It forces a rigid delay that’s often too short on a sluggish network (causing a failure) or way too long on a fast one (just wasting time).
The better way is to lean into Cypress's powerful, built-in retry-ability. Instead of just waiting for time to pass, make an assertion about the state you're actually waiting for. A command like cy.get('.my-element').should('be.visible') tells Cypress to intelligently wait for that element to appear before moving on. It’s smarter, more reliable, and way more efficient.
Stop letting flaky tests and CI bottlenecks slow you down. Mergify's Merge Queue and CI Insights give you the tools to build a stable, efficient, and reliable development pipeline. Start optimizing your workflow today.