A Practical Guide to Fixing Flaky Cypress Tests

We’ve all seen it happen. A perfectly good pull request fails its CI checks. A developer, confused but determined, digs in to find the problem. They re-run the pipeline, and... it passes. No code changes, nothing. Just a magical green checkmark.
This is the classic, frustrating signature of a flaky Cypress test. These aren't just small technical hiccups; they're major roadblocks that slowly poison your team's confidence, burn through valuable engineering time, and bring your entire development cycle to a crawl.
The True Cost of Unreliable Tests
When tests become unpredictable, a dangerous "boy who cried wolf" scenario starts to unfold. Developers begin to distrust the test suite, automatically writing off any failure as "just another flaky test." This kind of complacency is a huge risk, as it’s the perfect cover for real regressions to sneak right into production, completely defeating the purpose of having automated tests in the first place.
Why Flakiness Spreads
The damage from a flaky test doesn't stop at a single failed pipeline. It creates a ripple effect that hurts both productivity and morale.
Here’s what that looks like in the real world:
- Wasted Developer Time: Engineers get pulled away from building features to chase down ghosts, re-running pipelines and debugging problems that don't actually exist.
- Delayed Deployments: A single flaky test can block a critical release, delaying new features for your customers and throwing your entire release schedule off track.
- Loss of Confidence: Soon, everyone—from engineers to product managers—loses faith in your automated quality gates.
- Increased CI Costs: Every time someone re-runs a job, it eats up more CI minutes. This drives up your operational costs without adding any real value.
To really appreciate why this is so damaging, it's helpful to have a solid grasp of quality assurance in software development and its role as the bedrock of a healthy engineering practice.
Flakiness isn't just an annoyance; it's a direct threat to your team's velocity and the quality of your product. Ignoring it means accepting a slower, less reliable, and more expensive development process.
A mid-2024 analysis comparing Cypress and Playwright found that Cypress has an average flakiness rate of about 0.83% across over 318 million test records. While that number might seem small, the worst-performing projects hit rates as high as 4.2%—a figure that can absolutely paralyze a CI workflow. You can read the full analysis on Cypress vs Playwright flakiness to understand the data better.
Tackling flaky Cypress tests isn't just about writing cleaner code; it's a critical investment in building a healthy, productive, and trustworthy engineering culture.
Common Symptoms of Flaky Tests
Recognizing the signs of flakiness is the first step toward fixing it. If you're seeing any of these patterns, it’s a good indicator that you have flaky tests lurking in your suite.
| Symptom | Description | Immediate Impact |
|---|---|---|
| Pass/Fail Inconsistency | The same test passes and fails on the same code without any changes. | Erodes trust in the test suite. |
| "Works on My Machine" | Tests pass locally but consistently fail in the CI environment. | Creates a bottleneck for merging pull requests. |
| Timing-Related Failures | Tests fail with timeouts, element-not-found, or detached DOM errors. | Indicates race conditions or slow-loading resources. |
| Order-Dependent Failures | A test only fails when run after another specific test or in a certain order. | Suggests state is leaking between tests. |
Seeing these symptoms is a clear signal to stop what you're doing and investigate. Letting them slide only allows the problem to grow, making it much harder to fix down the line.
Identifying the Root Causes of Flakiness
Trying to pin down the exact reason for a flaky Cypress test can feel like you're chasing a ghost. One minute it fails, the next it passes, and you haven't touched a single line of code. These inconsistencies aren't random—they're almost always symptoms of deeper issues in your test design, application state, or even the testing environment itself.
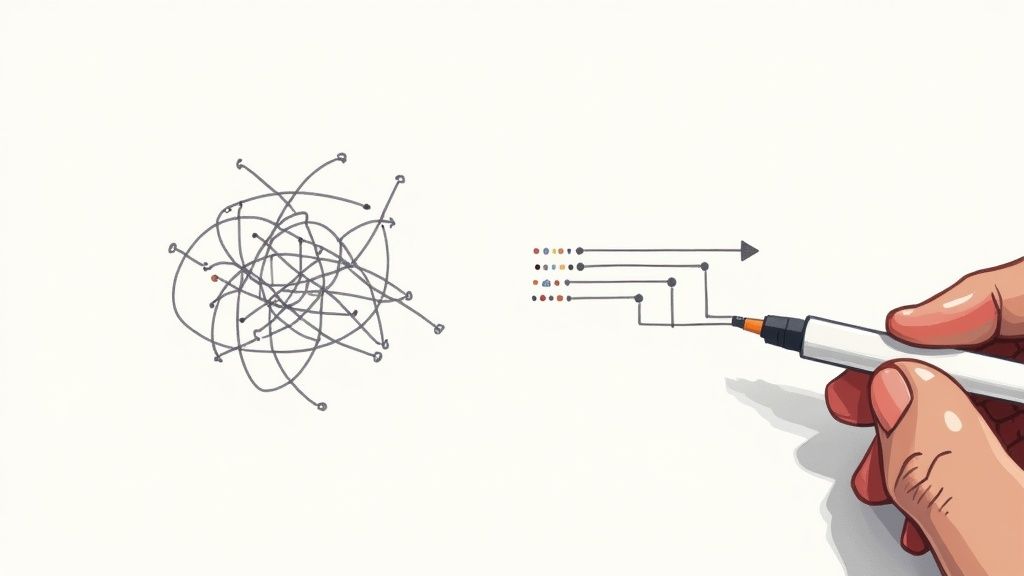
First things first, you need a mindset shift. Stop just rerunning the CI pipeline and crossing your fingers. Instead, start treating every flaky failure as a legitimate bug report for your test suite. This simple change moves you from playing whack-a-mole to building a genuinely reliable set of tests.
This decision tree nails the frustrating loop so many developers get stuck in when a flaky test breaks the build.
The big takeaway here is that just hitting "rerun" is a band-aid. It hides the real problem and slowly chips away at your team's trust in the entire test suite.
Asynchronous Operations and Timing Issues
If I had to bet, I'd say your flaky test is caused by an async issue. Modern web apps are a whirlwind of activity—fetching data, rendering components, and responding to clicks, all happening at unpredictable times. Cypress, on the other hand, runs its commands in a neat, orderly line and can easily get out of sync with what the application is actually doing.
This mismatch is a classic recipe for a race condition. The test tries to interact with something before it’s ready, like clicking a button that hasn't appeared because an API call is still pending. It’s no surprise that one survey found around 37% of Cypress test failures are tied to bad waits or timing problems where Cypress plows ahead before the app has caught up.
Here's a textbook example of a test that’s flaky by design:
it('fails intermittently when data loads slowly', () => {
cy.visit('/dashboard');
// This command might run before the API call finishes
cy.get('[data-cy="welcome-message"]').should('contain', 'Welcome, User!');
});
This test will probably pass on a fast network. But the moment an API response lags, it fails. That’s the definition of a flaky test.
Unstable Selectors and DOM Changes
Another huge source of flakiness comes from using selectors that are just too brittle. If you're selecting elements based on CSS classes or complex DOM paths like div > span:nth-child(2), you're setting yourself up for failure. A minor UI tweak by a developer, and boom—your test is broken.
A far better approach is to use dedicated test attributes.
- Avoid This:
cy.get('.btn-primary.submit-btn') - Do This Instead:
cy.get('[data-cy="submit-login"]')
Using data-cy attributes creates a stable agreement between your app and your tests. It decouples the test from styling or structural changes, making it exponentially more resilient. For a deeper dive, check out this developer's guide on flaky test detection and prevention.
Your test selectors should describe an element's function, not its appearance. Adopting this one rule will wipe out an entire category of flaky tests.
Inconsistent Test Environments
Sometimes, the problem isn't your code—it's the environment it's running in. The classic "it works on my machine" headache often comes down to differences between your local setup and the CI server.
These environmental quirks can show up in a few ways:
- Resource Constraints: Your CI runner might have less CPU or memory, causing your app to render more slowly than it does for you.
- Network Latency: The network in a cloud CI environment can be wildly unpredictable, delaying API responses.
- Configuration Drift: Subtle differences in environment variables, browser versions, or even operating systems can cause tests to fail.
To get to the bottom of this, try running your tests locally in headless mode to better mimic the CI environment. And don't forget to use Cypress's video and screenshot artifacts on failure. Seeing what the browser actually saw on the CI server can reveal issues that logs alone will never catch.
Practical Strategies for Fixing Flaky Tests
Alright, we know what causes flaky tests. Now for the fun part: fixing them. It’s time to move from diagnosis to action with a few reliable, repeatable strategies that will build stability right into your test suite.
Think of these techniques less like quick hacks and more like foundational patterns for writing professional-grade automation. The real goal here is to stop reacting to failures and start writing tests that anticipate the dynamic, asynchronous nature of modern web apps. By mastering a few key Cypress commands and principles, you can wipe out entire categories of flaky behavior for good.
Master Network Requests with cy.intercept
If there's one tool you need to have in your arsenal, it's cy.intercept(). This command is a game-changer. It gives you complete control over network requests, letting your tests stop guessing and start waiting intelligently. It is the definitive solution for any race condition where your test outpaces your API.
Instead of tossing in a clumsy cy.wait(1000) and crossing your fingers, you can tell Cypress to pause and wait for a specific network call to finish.
Here's a test that's a ticking time bomb. It only passes if the /api/dashboard call resolves before Cypress's default timeout. We've all written this at some point.
The Flaky Way:
it('loads user data and displays a welcome message', () => {
cy.visit('/dashboard');
// This might run before the data is on the page
cy.get('[data-cy="user-greeting"]').should('contain', 'Welcome back!');
});
Now, let's make it rock-solid. We'll explicitly tell the test to wait for the data it needs. This makes the test completely immune to network slowdowns.
The Rock-Solid Way:
it('waits for user data before asserting the welcome message', () => {
// Intercept the API call and give it an alias
cy.intercept('GET', '/api/dashboard').as('getDashboardData');
cy.visit('/dashboard');
// Now, explicitly wait for the aliased request to complete
cy.wait('@getDashboardData');
// This assertion now runs with total confidence
cy.get('[data-cy="user-greeting"]').should('contain', 'Welcome back!');
});
This simple change transforms a flaky test into a reliable one. You're no longer testing against a clock; you're testing against the actual state of your application.
Achieve True Test Isolation
Another huge source of flakiness is state leakage, where one test accidentally messes up the next one. The classic example? A test logs a user in but never logs them out, so the next test starts in a weird, unexpected authenticated state and immediately fails.
The golden rule is this: every test must be able to run independently and in any order. To get there, you have to programmatically manage your application's state before each and every test.
"A test that relies on another test to set up its state is not a test—it's a liability. True test isolation is non-negotiable for a stable and scalable test suite."
Here are the best ways to enforce total isolation:
- API Calls for Setup: Use
cy.request()inside abeforeEachhook to handle setup tasks. You can programmatically log in, create data, or reset the database to a known starting point. It’s far faster and more reliable than clicking through the UI. - The Power of
cy.session(): For managing login states,cy.session()is incredible. It caches the browser session (cookies, local storage, etc.) after a successful login, letting all your other tests restore that state instantly. No more logging in through the UI for every single test. - Database Seeding: For tests that need very specific data, use tasks or scripts to seed your test database before the run even begins. This guarantees your application starts in a predictable state every single time.
By isolating your tests, you eliminate that chaotic domino effect where one tiny failure triggers a cascade of unrelated errors across your entire suite.
Create Custom Commands for Complex Interactions
Does your app have a common, multi-step process you test all the time? Maybe a fancy date picker or a complex form wizard? Repeating those same steps in every test isn't just inefficient—it creates multiple points of potential failure.
This is where custom commands shine. They let you bundle complex UI interactions into a single, reusable function. Your tests become cleaner, more readable, and way easier to maintain. If that complex component's UI ever changes, you only have to update the custom command in one place, not in dozens of test files.
Let's look at a test for adding an item to a cart.
Without a custom command, it's a bit noisy:
it('adds a product to the cart', () => {
cy.get('[data-cy="product-grid"]').first().click();
cy.get('[data-cy="select-size-dropdown"]').select('M');
cy.get('[data-cy="add-to-cart-button"]').click();
cy.get('[data-cy="cart-notification"]').should('be.visible');
});
Now, let's abstract that logic into its own command.
With a custom command, it's clean and declarative:
First, you define the command in cypress/support/commands.js:
Cypress.Commands.add('addToCart', (productIndex, size) => {
cy.get('[data-cy="product-grid"]').eq(productIndex).click();
cy.get('[data-cy="select-size-dropdown"]').select(size);
cy.get('[data-cy="add-to-cart-button"]').click();
});
Then, your test becomes wonderfully simple and descriptive:
it('adds a product to the cart', () => {
cy.addToCart(0, 'M');
cy.get('[data-cy="cart-notification"]').should('be.visible');
});
This approach centralizes complex logic, making your test suite more robust and far less prone to those frustrating intermittent failures caused by tricky UI interactions.
Building a Reliable Testing Environment
Fixing individual flaky Cypress tests is a crucial skill, but the real win is building an entire ecosystem that prevents flakiness from ever taking root. To do that, you have to zoom out from single lines of code and focus on the environment where your tests run. A stable, predictable environment is the bedrock of a trustworthy test suite.
The classic "it works on my machine" problem is the first enemy to defeat. It almost always points to inconsistencies between a developer's local setup and the CI/CD server. This is where containerization becomes your most powerful ally.
Embrace Deterministic Environments with Docker
Using Docker containers for your CI jobs is an absolute game-changer for consistency. A Dockerfile explicitly defines everything—the operating system, browser version, dependencies, and environment variables. This forces every single test run, whether on a local machine or in the cloud, to execute in an identical, controlled environment.
This one practice eliminates an entire class of flaky tests caused by subtle environmental drift. No more surprises from an unexpected browser update or a missing dependency on the CI runner.
By making your testing environment as deterministic as your code, you systematically remove variables that contribute to flaky Cypress tests. If it passes in a Docker container locally, you can have high confidence it will pass the same way in CI.
Control External Dependencies and Network Conditions
Your tests shouldn't be at the mercy of a third-party API outage or a sluggish network connection in your CI environment. The goal is to isolate your application so you’re testing its logic, not the reliability of its dependencies.
Here are a couple of effective strategies for achieving this isolation:
- Comprehensive Mocking: Use
cy.intercept()for more than just waiting on requests. Use it to completely mock external services. This guarantees your tests receive a consistent, predictable response every single time, regardless of the real service's status. - Service Virtualization: For more complex scenarios, dedicated tools can simulate the behavior of entire backend systems. This lets you test intricate workflows without any real network traffic ever leaving your test runner.
Properly managing test environments is a deep topic, but mastering dependency control is a massive step toward more reliable automation.
Implement a Quarantine and Analysis Process
Even with the best environment, a flaky test might still slip through. Instead of letting it block your entire pipeline, you need a process to manage it. The Cypress Dashboard is invaluable here, as it automatically flags tests that pass after a retry, giving you a clear signal of flakiness.
When a test gets flagged as flaky, here’s what to do:
- Quarantine It: Move the test to a separate "quarantine" suite. This allows the main CI pipeline to stay green, preventing the flaky test from blocking deployments while you investigate.
- Analyze Patterns: Use the Dashboard to review its history. Does it only fail in a specific browser? At a certain time of day? This data provides crucial clues to the root cause.
- Prioritize the Fix: Dedicate real time to fixing quarantined tests. A growing quarantine suite is a major red flag that your technical debt is piling up.
This structured approach ensures that one unstable test doesn't derail your team's productivity while providing the data needed for an effective fix.
Advanced Tooling and Future-Proofing Your Test Suite
Once you've wrestled your existing tests into a stable state, it's time to think bigger. The real goal isn't just fixing today's problems but building a test suite that stays healthy as your application grows. This means looking past the quick fixes and adopting strategies that prevent flaky Cypress tests from ever taking root.
A great place to start is with a tool you already have: Cypress’s built-in Test Retries feature.
While it’s a powerful tool, think of Test Retries as a safety net, not your first line of defense. Turning on retries in your CI environment can be a lifesaver, catching those random, unpredictable failures from a network hiccup or a momentary resource spike. But be careful. Leaning on it too heavily just masks deeper issues like stubborn race conditions.
The Rise of AI in Test Automation
The whole testing landscape is shifting, and AI-powered tools are becoming a serious ally in the fight against flakiness. The trend is clear: by 2025, Agile teams that want truly reliable CI/CD pipelines will be turning to advanced automation frameworks.
These aren't just your standard test runners. They analyze historical failure data to predict which tests are most likely to go rogue and can even suggest potential fixes. It’s a move from being reactive to proactive. For a deeper look, the top benefits of AI in Software Testing are worth exploring to see how it can bolster your test suite's stability and efficiency.
Visual regression testing is another critical layer for future-proofing. It catches those sneaky UI changes—like a button shifting a few pixels—that won't break a functional test but can definitely mess with user experience or introduce subtle flakiness.
These tools work by snapping a baseline screenshot of a component or an entire page. On subsequent test runs, they compare the new screenshot to the baseline and flag any visual differences.
Cypress needs a third-party plugin to get this done, but it’s a high-impact integration. It helps you catch a whole class of bugs that traditional end-to-end tests completely miss.
If you’re curious about what other frameworks are doing in this space, our guide on end-to-end testing with Playwright offers a different perspective on modern tooling. By combining smart retries, AI-driven analysis, and solid visual validation, you’re not just fixing tests—you're building a resilient testing strategy that can actually scale with your product.
Got Questions About Flaky Cypress Tests?
When you're deep in the weeds trying to stabilize a test suite, a few common questions always seem to pop up. Let's tackle them head-on, based on what we've seen work (and what hasn't).
Should I Just Crank Up The Default Timeout?
It's tempting, I get it. One flaky test, and your first instinct might be to just globally increase defaultCommandTimeout. But this is a classic trap. It's a blunt instrument that slows down your entire test suite just to accommodate one or two slowpokes.
A much smarter approach is to give extra time only where it's absolutely needed. You can apply a specific timeout directly to a command that you know might take longer.
cy.get('[data-cy="slow-loading-element"]', { timeout: 10000 }).should('be.visible');
This way, your fast tests stay fast, and you're only patient with the elements that genuinely need it. A global increase is often just putting a band-aid on a deeper performance issue or a tricky race condition.
So, Is It Ever Okay to Use cy.wait()?
Let's be clear: using cy.wait() with a hardcoded number, like cy.wait(2000), should be your absolute last resort. It's a code smell. It introduces arbitrary delays and makes your tests incredibly brittle. What happens when your staging environment is a little sluggish and that element takes 2.5 seconds to appear? The test fails.
Hardcoded waits are almost always a sign that you're not properly waiting for your application to be in the right state.
The only time cy.wait() is your friend is when you're waiting for an aliased network request using cy.intercept().
cy.wait('@getData')tells Cypress to pause until a specific, known event has actually finished. It's deterministic.cy.wait(2000)is just a wild guess, and guessing is the fastest way to build a flaky test suite.
How Do I Deal With All These UI Animations?
Ah, animations. They look great to users but are a frequent source of chaos for automated tests. Cypress might try to click a button just as it's sliding into place, leading to a failed test because the element was technically "in motion."
The best, most reliable solution? Just turn them off in your test environment.
You can usually inject a small CSS override that disables all transitions and animations when Cypress is running the show. This ensures your app's UI state changes are instant and predictable, completely sidestepping a whole class of timing-related headaches.
Dealing with flaky tests shouldn't be a full-time job that slows down your team. Mergify’s Merge Queue and CI Insights are designed to keep your pipeline green and reliable. We help prevent broken code from ever hitting your main branch and give you the observability needed to squash infrastructure problems quickly. Stop fighting your CI and start shipping faster with Mergify.