GitLab CI CD Your Guide to Modern Automation

GitLab CI/CD is a powerful tool built directly into the GitLab platform that completely automates how you build, test, and deploy software. Think of it as a digital assembly line for your code. It ensures every single change is automatically validated and shipped out, both quickly and reliably.
This deep integration brings the entire software development lifecycle into one, cohesive workflow.
What Is GitLab CI CD and Why Does It Matter?
Let's picture your development process without any automation. A developer finishes writing some code, then has to manually kick off a series of tests. If everything passes, they package up the application and toss it over the fence to another team for deployment. You can see the problem here.
This chain of manual hand-offs is slow, incredibly prone to human error, and creates bottlenecks that keep valuable features from ever reaching your users. Every tiny change forces you to repeat the whole tedious sequence.
GitLab CI/CD completely flips this script by introducing two core practices: Continuous Integration (CI) and Continuous Delivery/Deployment (CD). It acts as an automated quality gate and delivery machine that springs into action the moment a developer commits new code. This system transforms that slow, disjointed manual mess into a fast, transparent, and dependable workflow.
The Power of Integrated Automation
At its heart, CI/CD is all about two things: speed and reliability. By automating all the repetitive tasks, your teams can get back to focusing on what they do best—writing great code—instead of getting bogged down in the manual muck of deployment chores.
The "CI" part of the equation ensures that new code from all your different developers gets integrated into a central repository, and it happens frequently. Each one of these integrations triggers an automated build and a sequence of tests.
Key Takeaway: The whole point of Continuous Integration is to find and squash integration bugs early and often. By testing every small change automatically, teams can spot and fix problems while they're still small and manageable, not right before a massive release.
Continuous Delivery (or Deployment) takes this a step further. As soon as the code passes all its automated tests, it’s automatically prepared for release.
Adopting a GitLab CI CD workflow unlocks some huge benefits:
- Faster Release Cycles: Automation slashes the time it takes to get from a code commit to a production deployment. This means you can deliver value to your users way more often.
- Improved Code Quality: When you're running automated tests on every single change, bugs get caught much earlier in the development cycle. The result is a more stable product.
- Reduced Risk: Automated processes are consistent and repeatable. This eliminates the kind of human errors that inevitably pop up during manual deployments.
- Enhanced Developer Productivity: Developers can merge their code with confidence, knowing an automated system has their back and will validate their work. This frees them up to move on to the next task faster.
Understanding the Building Blocks of a Pipeline
To really get the hang of GitLab CI/CD, you first need to know what it's made of. Think of it like a set of LEGO bricks—each piece has a specific job, and you connect them in a logical order to build something powerful and automated. The entire process is orchestrated from a single, central file that acts as the master blueprint for your whole workflow.
This blueprint is a YAML file named .gitlab-ci.yml. It has to live in the root directory of your project. This is where you define every single step, from building the application all the way to deploying it. Every time you push code, GitLab looks for this file to know exactly what to do.
This configuration file is the heart of any GitLab CI/CD process. Its popularity reflects a huge industry shift toward integrated development tools. In fact, by early 2024, GitLab's customer base had grown to over 30,000 paying organizations, including more than half of the Fortune 100. You can discover more insights about GitLab's market expansion to see what this means for modern development teams.
The Core Components Hierarchy
To make sense of the .gitlab-ci.yml file, it helps to understand how its main elements are layered. These components work together in a structured, top-down relationship where each level contains the next.
This diagram shows how the main blocks within the .gitlab-ci.yml file—like build, test, and deploy—are structured as distinct jobs within the pipeline.
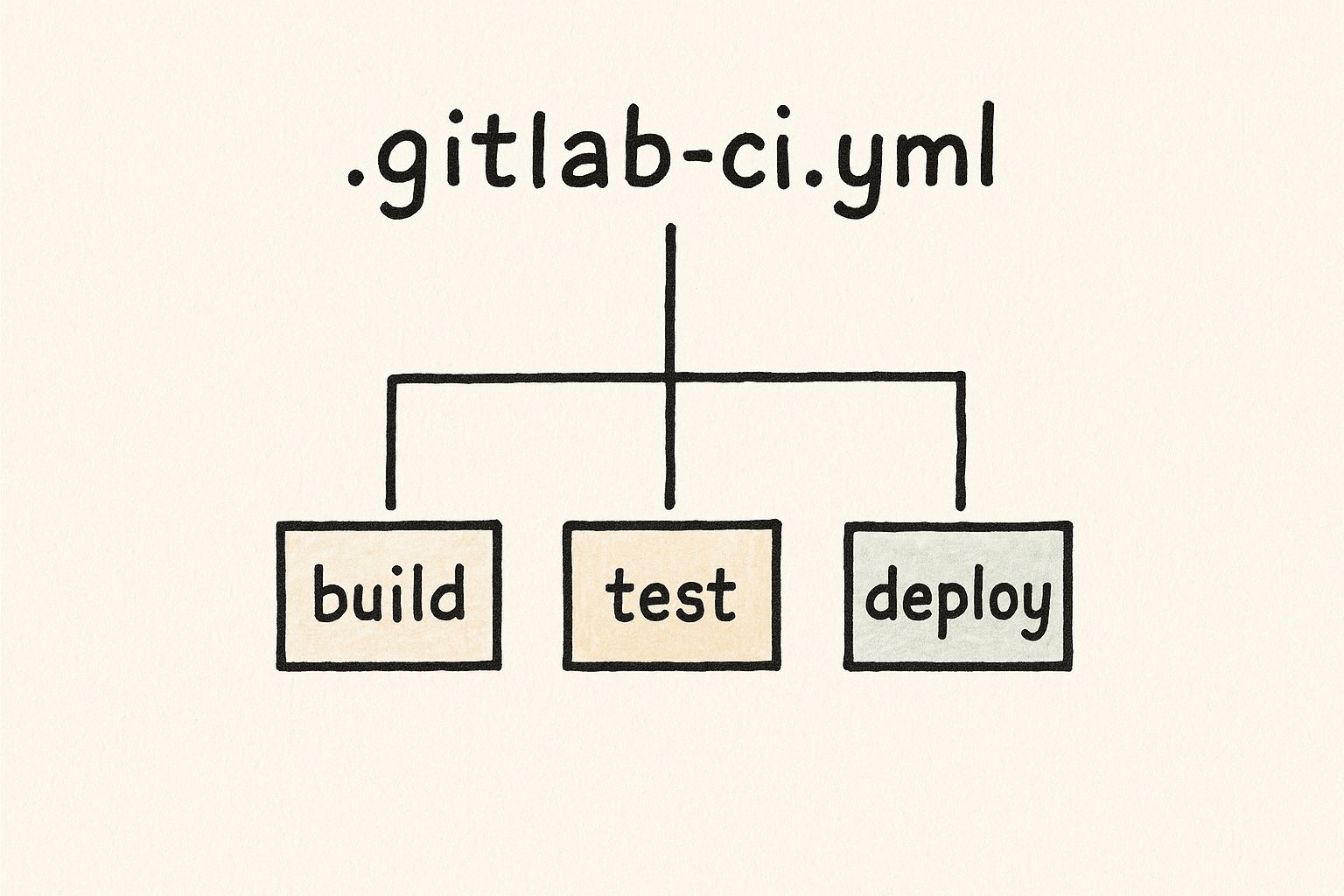
As you can see, the Pipeline is the highest-level concept. It wraps everything up, containing Stages, which in turn contain the individual Jobs that get executed.
At the very top, you have the Pipeline. A pipeline represents the complete workflow that runs for a single code change. It’s the entire CI/CD process from start to finish.
Next up are Stages. Stages are just logical groupings of jobs. For example, it’s common to create a build stage, a test stage, and a deploy stage.
A critical rule in GitLab CI/CD is that all jobs within a single stage run in parallel. The pipeline will only proceed to the next stage after all jobs in the current stage have completed successfully.
This structure gives you a clean, organized way to control the flow of your automation. It’s how you guarantee your code gets built before it’s tested, and tested before it's deployed.
Jobs and Runners: The Action Takers
Inside each stage, you'll find one or more Jobs. A job is the most basic unit of work—it's a specific command or script that needs to run. For instance, a job could be compiling code, running a suite of unit tests, or pushing a Docker image to a container registry.
Jobs define what to do. But what about where the work happens? That's where Runners come in.
A GitLab Runner is an agent that picks up and executes your CI/CD jobs. Think of it as a dedicated worker machine just waiting for instructions. When a job is ready to run, GitLab assigns it to an available Runner, which then executes the script you defined in your .gitlab-ci.yml file.
You can use shared Runners provided by GitLab or set up your own for more control over the environment. This separation—defining work in jobs and executing it on Runners—is what makes the whole system so flexible and scalable.
To pull it all together, here's a quick breakdown of how these components fit into the bigger picture.
Key GitLab CI CD Components at a Glance
| Component | Role and Description | Example Usage |
|---|---|---|
.gitlab-ci.yml |
The main configuration file. It's the blueprint that defines the entire CI/CD process for a project. | Located in the project's root, it contains all stages, jobs, and scripts. |
| Pipeline | The top-level workflow. A pipeline is triggered by an event, like a code push, and runs all defined stages and jobs. | A full run of your build, test, and deployment process. |
| Stage | A logical grouping of jobs. Stages define the execution order of the pipeline. | build, test, security_scan, deploy_staging, deploy_production |
| Job | The most granular unit of work. It’s a set of commands or a script that performs a specific task. | compile-code, run-unit-tests, build-docker-image |
| Runner | The agent that executes the jobs. It's the machine (virtual or physical) where the work actually happens. | Can be a shared GitLab runner or a self-hosted runner on your own infrastructure. |
Understanding these five core building blocks is the first major step. Once you're comfortable with how they interact, you'll find it much easier to design and troubleshoot your own CI/CD workflows.
Key Features That Accelerate Your Workflow
So, what makes GitLab CI/CD the go-to choice for so many development teams? It’s not just one standout feature, but a whole suite of powerful, built-in tools that come together to create a remarkably smooth development experience.
This isn't about just bolting on a few extra capabilities. These features are designed to work in concert, cutting down on the usual friction points and toolchain headaches that slow teams down. The goal is to get you from code to cloud, faster.
The demand for this kind of integrated solution is exploding. The entire global market for CI/CD tools is on a steep upward curve, and forecasts predict it will blow past $15 billion in the next few years. That's a massive signal that teams are all-in on automating their software delivery.
Native Integration with Source Code Management
One of GitLab’s biggest wins is how its CI/CD is baked right into its source code management (SCM). Think about it: most other tools need you to set up clunky plugins or webhooks to talk to your code repository. GitLab CI/CD is already there, living right alongside your code.
This single-app approach is a game-changer. You don't have to juggle separate user accounts, permissions, or hooks between your SCM and your CI/CD system. You push your code, and GitLab just knows it's time to kick off a pipeline. It simplifies everything and creates a truly unified workflow from the get-go.
Auto DevOps for Zero-Configuration Pipelines
Jumping into CI/CD for a new project can feel like a mountain to climb. GitLab’s Auto DevOps feature basically gives you a massive head start. It provides a pre-built, best-practices pipeline that can automatically build, test, and deploy your application with almost no setup required.
Auto DevOps is smart. It peeks at your source code, figures out the language and framework you’re using, and then builds out a complete CI/CD pipeline for you based on industry standards. It's like having a DevOps pro set up your initial workflow in minutes.
For teams that just need to get moving, this is huge. It handles everything from security scanning to performance testing and deployment, giving you a rock-solid foundation that you can always tweak and customize later as your project grows.
Built-In Security Scanning (DevSecOps)
These days, security isn't just a final checkbox; it has to be part of the entire development process. GitLab gets this and embeds security scanning directly into the CI/CD pipeline, making a DevSecOps approach incredibly straightforward.
This includes a full suite of scans:
- Static Application Security Testing (SAST): Hunts for vulnerabilities in your source code.
- Dynamic Application Security Testing (DAST): Probes your running application for security holes.
- Dependency Scanning: Checks all your project's dependencies for known issues.
- Container Scanning: Scans your Docker images for security weak points.
By running these checks automatically with every single commit, developers get instant feedback. This means they can squash security bugs early on, long before they ever get near production—which is way cheaper and less stressful for everyone.
Review Apps and Live Previews
Getting good, clear feedback is what separates great software from the rest. This is where GitLab's Review Apps really shine. For every single merge request, this feature spins up a live, running environment of your application.
Instead of just reviewing lines of code, stakeholders like designers, product managers, and QA testers can actually see and interact with the proposed changes. It's a live preview. This closes the feedback loop in a dramatic way. Team members can spot UI glitches or usability problems that are impossible to catch in a code review, which you can see when looking at this comparison of modern CI/CD tools. It ensures what gets merged is what the team actually intended to build.
Flexible and Scalable Runners
The workhorses of GitLab CI/CD are its Runners—the agents that actually execute your pipeline jobs. GitLab gives you a ton of flexibility here. You can start with shared Runners managed by GitLab, which are free and perfect for open-source projects or just getting your feet wet without any infrastructure setup.
But when you need more power or control, you can easily set up your own self-hosted Runners. This gives you total command over the execution environment. Need specific software installed? Want to use beefier hardware? Need to run jobs on Windows, macOS, or Linux? No problem. This hybrid approach lets you scale your CI/CD muscle exactly how you need to.
How to Build Your First GitLab CI/CD Pipeline
Theory is great, but there's no substitute for getting your hands dirty. The best way to really get GitLab CI/CD is to build something with it. So, let's walk through creating your very first pipeline from the ground up. We'll keep it simple—a basic two-stage workflow—to get you comfortable with the core concepts.
Everything is controlled by a single, powerful file: .gitlab-ci.yml. Think of this as the blueprint for your automation. You just need to create it in the root directory of your GitLab project, and every time you push new code, GitLab will read this file to know exactly what to do.
Setting Up the Initial .gitlab-ci.yml File
First things first, let's create that .gitlab-ci.yml file in your project's root. The initial setup is all about defining the pipeline's overall structure. We’ll specify a base Docker image for our jobs to run in and then define the stages that make up our workflow.
The image is like the operating system and environment for your job. For this example, we’ll use a lightweight Alpine Linux image, a popular choice for quick and simple tasks. The stages keyword is crucial—it sets the execution order. Jobs in the build stage will always run before jobs in the test stage.
image: alpine:latest
stages:
- build
- test
This simple config doesn't actually run any tasks yet, but it puts the foundational sequence in place. All jobs in the build stage must pass before the pipeline can even think about moving on to the test stage. This sequential control is the bedrock of reliable automation.
Creating Your First Job
Alright, let's add our first job. A job is just a set of instructions that a GitLab Runner will execute. We'll create a simple build-job that belongs to our build stage. We do this by adding a new block to our YAML file.
The script keyword is where the magic happens—it’s a list of shell commands that the Runner will execute one by one. In this case, our job will simply print some text to the console.
build-job:
stage: build
script:
- echo "Compiling the code..."
- echo "Compile complete."
With that, our build-job is officially linked to the build stage. When the pipeline kicks off, the Runner will execute those two echo commands. It’s a basic example, but it perfectly shows how a job is defined and assigned to a specific stage in your workflow.
Adding a Testing Job and Using Artifacts
With a build job in place, the next logical step is to test our work. Let's add a test-job to the test stage. This job will pretend to run tests on whatever our build process created. But how does the test job get the output from the build job? That’s where artifacts come in.
Artifacts are files or directories that a job generates, which you can then pass along to other jobs in later stages.
Key Concept: Artifacts are the bridge between your pipeline stages. They let you preserve the output of one job (like a compiled binary or a test report) and make it available to another, ensuring the workflow continues seamlessly.
Let's tweak our build-job to create a dummy file and save it as an artifact. Then, our test-job will be able to access that file.
build-job:
stage: build
script:
- echo "Compiling the code..."
- mkdir build
- echo "This is a build artifact." > build/info.txt
- echo "Compile complete."
artifacts:
paths:
- build/
Now, we can create the test-job that uses this artifact. Notice how it's assigned to the test stage, ensuring it runs after the build is done.
test-job:
stage: test
script:
- echo "Running tests..."
- ls -l build/
- cat build/info.txt
- echo "Tests complete."
Once you commit this complete .gitlab-ci.yml file to your repository, GitLab automatically picks it up and runs your first pipeline. You can watch its progress right in the GitLab UI.
Here’s what a successful multi-stage pipeline looks like in the GitLab interface.
This visual gives you instant confirmation that all jobs in the build stage finished successfully before the test stage even began, perfectly demonstrating the sequential control that stages provide.
While this example uses simple echo commands, the principles are identical for complex, real-world applications. You’d just swap these lines with your actual build scripts, test runners, and deployment commands. For more advanced control, you can check out this complete guide to GitLab CI variables for your pipeline configuration to manage dynamic data and secrets securely.
With this foundation, you’re ready to start automating your own projects.
Once you’ve got the basic building blocks of your GitLab CI/CD pipeline down, it's time to start exploring the more powerful techniques. These are the features that take a simple, linear workflow and turn it into a smart, efficient, and secure automation engine that can handle the messy realities of modern development.
Moving beyond basic build and test stages is where the magic really happens. We're talking about securely managing secrets, slashing pipeline run times, and building dynamic, intelligent workflows. It’s the difference between a simple assembly line and a fully automated, smart factory.
This is exactly why GitLab has earned such a strong reputation. In the crowded CI/CD space, GitLab holds serious mindshare, especially when it comes to build automation. The whole CI/CD market is expected to more than triple over the next decade, and that growth is being driven by the demand for integrated platforms like GitLab. You can see more on the top CI software in 2025 and how this all-in-one approach is winning teams over.
Managing Secrets with CI/CD Variables
Let's get one thing straight: hardcoding sensitive data like API keys, database passwords, or access tokens directly into your .gitlab-ci.yml is a massive security blindspot. Anyone with access to your repo can see them. The right way to handle secrets is with CI/CD variables.
Think of them as key-value pairs you define in the GitLab UI, either for a specific project or an entire group. You can flag them as protected, so they’re only available to protected branches, and masked, which keeps their values hidden in job logs.
Best Practice: Always, always use masked and protected CI/CD variables for any sensitive data. This keeps your configuration separate from your code and is a cornerstone of a secure pipeline. For a deeper dive, check out these essential CI/CD security best practices to help lock down your automation.
When a job kicks off, GitLab makes these variables available to the Runner's environment, so your scripts can access them just like any other environment variable.
Speeding Up Jobs with Caching
Does every pipeline run start with your jobs downloading the exact same dependencies all over again? This is a classic bottleneck that burns through time and resources. GitLab’s cache keyword is the fix, letting you save files and directories between job runs.
You can set up a cache for your entire pipeline or on a per-job basis. A perfect use case is caching the node_modules directory for a JavaScript project or the .m2 repository for a Maven build.
cache:
key: ${CI_COMMIT_REF_SLUG}
paths:
- node_modules/
install-dependencies:
stage: build
script:
- npm install
With this in place, the node_modules directory gets cached. The next time the pipeline runs on the same branch, the Runner will find the cache and restore the directory instead of running npm install from scratch. That can easily shave minutes off every single run.
Gaining Granular Control with Rules
Sometimes, you need more precise control over when a job should run. Maybe you only want a deployment job to trigger for merge requests, or a test suite to run only on the main branch, or a script to execute only when specific files have changed. The rules keyword gives you this powerful conditional logic.
With rules, you define a list of conditions. GitLab checks them one by one until it finds a match, then decides whether to run the job or skip it entirely.
Here are a couple of real-world examples:
- Run a job only for merge requests:
deploy-review-app:
stage: deploy
script: echo "Deploying review app..."
rules:
- if: $CI_PIPELINE_SOURCE == "merge_request_event" - Run a job only when a specific file changes:
run-backend-tests:
stage: test
script: echo "Running backend tests..."
rules:
- if: $CI_COMMIT_BRANCH == "main"
changes:
- backend/**/*
This kind of control is crucial for building efficient pipelines that don't waste time and money running jobs that aren't needed.
Keeping Code DRY with Templates and Includes
As your pipelines get more sophisticated, you'll start noticing a lot of repeated configuration in your .gitlab-ci.yml files across different projects. To fight this repetition, GitLab supports templates using the include keyword. It lets you define reusable chunks of CI/CD configuration and pull them into your main file.
You can include files from the same project, from another project in your GitLab instance, or even from a remote URL. This "Don't Repeat Yourself" (DRY) principle makes your pipelines way easier to maintain, update, and scale, ensuring everyone in your organization is following the same best practices.
Answering Your Top GitLab CI/CD Questions
When teams first start digging into GitLab CI/CD, a few questions always seem to come up. Getting those answered early on really smooths out the learning curve and helps you tap into the platform's automation power much faster. Let's tackle some of the most common ones head-on.
Whether you're trying to decide between tools, figure out your infrastructure needs, or see how it plays with other platforms, having the right information is everything.
How Is GitLab CI/CD Different from Jenkins?
This is probably the number one question I hear, and the answer really comes down to one word: integration.
Jenkins is a beast. It's a powerful, standalone, open-source automation server that can do just about anything. But that flexibility comes at a price—it requires a lot of setup and integration work to connect with your source code tools like GitHub or Bitbucket.
GitLab CI/CD, on the other hand, is baked right into the GitLab platform. It’s not a separate tool you have to bolt on; it's a core feature of the same application where your code lives.
This unified approach gives you a few major wins:
- A Single Application: You manage your code, CI/CD pipelines, and security scanning all in one spot, with one user interface and permission model.
- Less Configuration Mess: Forget fiddling with complex plugins or webhooks just to get your repo talking to your CI system. It just works, right out of the box.
- A Natural Workflow: The whole process, from pushing code to seeing it deployed, feels completely connected because it's all happening in the same ecosystem.
While Jenkins offers endless customization, it often requires a dedicated team to manage the infamous "plugin hell" and the server itself. GitLab offers a much more streamlined, all-in-one experience that most teams find way easier to get started with and maintain.
What Are GitLab Runners and Do I Have to Host Them?
Think of GitLab Runners as the workers that actually execute the jobs in your CI/CD pipeline. They’re the agents that pick up the instructions from your .gitlab-ci.yml file and run the scripts on a machine somewhere. GitLab gives you a super flexible model for how to use them.
You’ve got two main options:
- Shared Runners: If your project is on GitLab.com, you get access to a fleet of Runners that GitLab maintains for you. They're free to use (with some monthly minute limits on the free tier) and are perfect for getting off the ground without any infrastructure setup.
- Self-Hosted Runners: You can install and register your own Runners on any machine you control—a server in your data center, a VM in the cloud, or even your local computer.
You don’t have to host your own Runners, but many organizations choose to for greater control. Self-hosting lets you customize the hardware, install specific software your jobs need, and keep all CI/CD work inside your own secure network.
This hybrid model really is the best of both worlds. You can start fast with shared Runners, then switch over to self-hosted ones as your project's security or performance needs get more serious.
Can I Use GitLab CI/CD with Other Git Repositories?
Yes, you absolutely can. While GitLab CI/CD is obviously at its best when paired with GitLab repositories, it's not a closed-off relationship. You can use its powerful pipeline features even if your code is sitting on another platform like GitHub or Bitbucket.
This feature is often called "CI/CD for external repos." By connecting your external repository to GitLab, you can use a .gitlab-ci.yml file in that repo to trigger and run pipelines inside GitLab. It's a fantastic way for teams to adopt GitLab’s top-notch automation without having to go through a massive codebase migration. You get the benefits of GitLab's features while keeping your existing repository structure exactly where it is.
Are you looking to optimize your CI/CD workflow and slash pipeline costs? Mergify provides an intelligent merge queue that automates pull request updates and batches CI runs, ensuring a stable and efficient development process. See how you can save developer time and reduce frustration at https://mergify.com.