How to Get Rid of Flaky Tests: 5 Tools to Know in 2026
A balanced 2026 guide to flaky test detection tools: Mergify Test Insights, BuildPulse, TestDino, Datadog Test Visibility, and CircleCI Test Insights. Pricing, fit, and honest limitations for each.

A flaky test is a test that produces different outcomes on the same SHA. Same code, same inputs, different result. The cost adds up faster than most teams realize: blocked merges, lost developer focus, retry storms in CI, and the slow erosion of trust that ends with engineers ignoring failures altogether.
Most engineering orgs reach for the same fixes in the same order. Retry the failed job. Mark the test as skip. Add a wait_for(2) and move on. None of those address the underlying problem, and none scale once your test suite passes a few thousand cases.
A real flaky test detection tool does four things: it detects which tests are inconsistent on the same SHA, it lets you quarantine them so they stop blocking merges, it gives you data to debug the root cause, and it integrates with the rest of your CI so the signal can change behavior. The six tools below cover the credible options in the market today. Each is presented with honest pros and cons, including the one we make.
1. Mergify Test Insights
Disclaimer up front: this is our product. We have included it because excluding it would be its own form of bias, and the integration angle is meaningfully different from the other entries on this list.
Mergify Test Insights ships as part of Mergify's broader merge queue and CI platform. The detection layer has deep framework ingestion and can also ingest JUnit XML the same way other tools do, but the differentiator is that the flakiness signal feeds from different sources. A quarantined test stops blocking merges automatically; the CI and merge queue treat its failure as a soft signal and merge anyway if the rest of the suite passes. Auto-retry runs at the queue layer, gated to known-flaky tests only so it does not hide real bugs.
It also has a unique prevention mechanism which stops flaky tests from entering the code base at the pull request level.
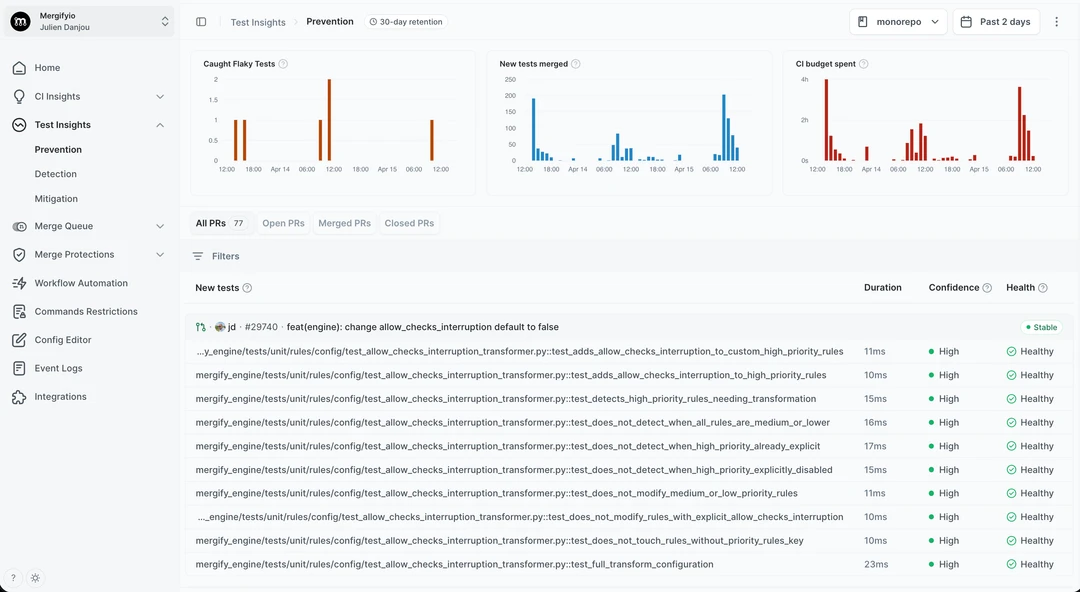
How detection works: Mergify ingests test runs from GitHub Actions, Jenkins, CircleCI, Buildkite, or any CI. Results are stored per SHA, and the flakiness page ranks tests by inconsistency across windows. Quarantine is opt-in per test and has a TTL to prevent tests from rotting in the holding pen.
Pricing: Included in every Mergify plan. Free tier for open source and small teams; paid plans scale with active contributors.
Best for: Teams that already use or are evaluating a merge queue, particularly at scale where flaky tests start blocking real engineering velocity. Tightest fit for teams that want detection, quarantine, and auto-retry to all live in the same place and influence merge behavior.
Where it falls short: GitHub-only on the merge side today. The product makes even more sense if you adopt Mergify's merge queue too, which is a bigger lift than installing a single-purpose detection tool.
Reference: mergify.com/product/test-insights
2. BuildPulse
BuildPulse is a specialty SaaS focused exclusively on flaky test detection. The product is narrower than the platforms in this list, which is its biggest strength. Teams get a tool that does one thing well, with a fast setup and a clear dashboard.
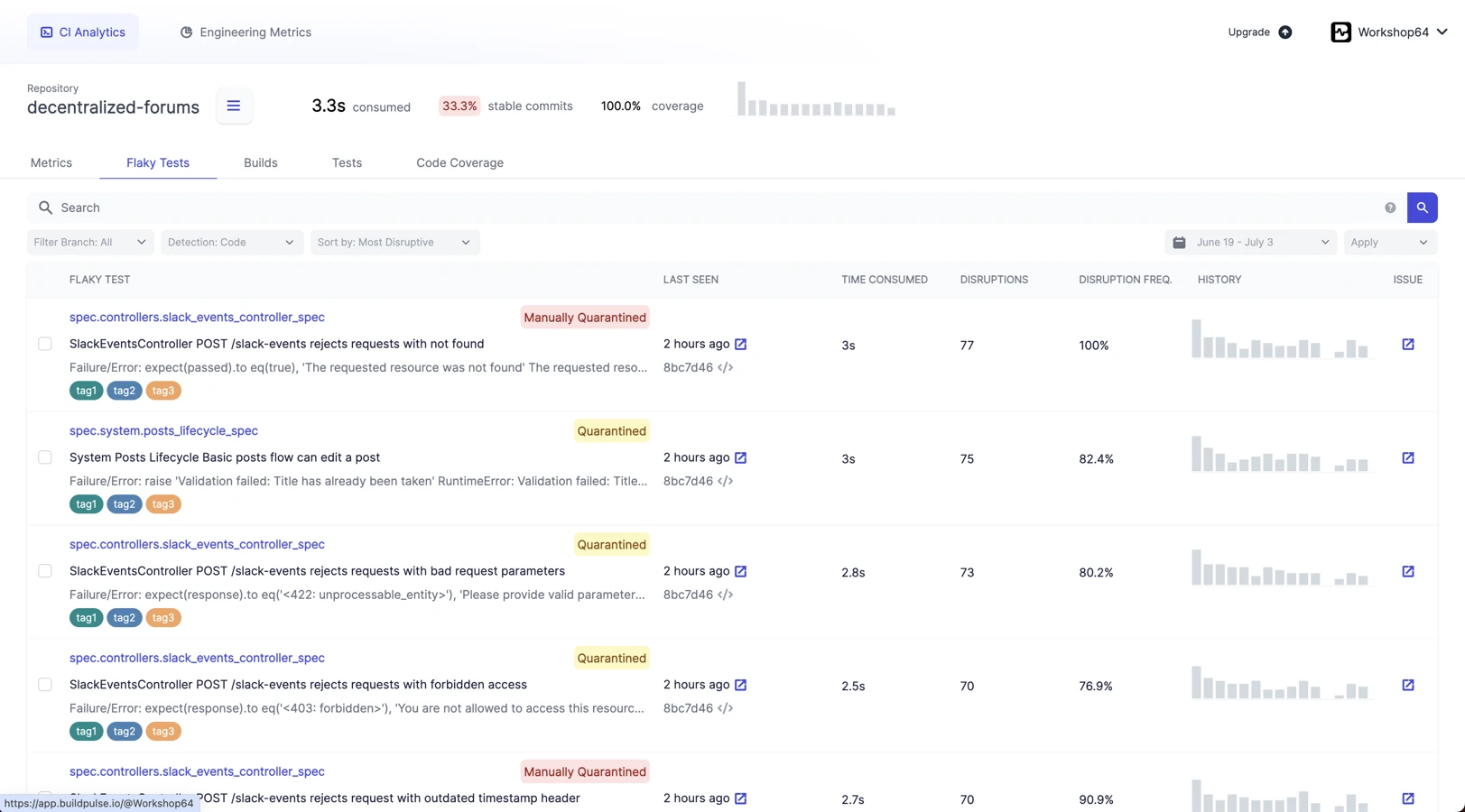
How detection works: BuildPulse hooks into your CI as a step that uploads test results after each run. It compares results across runs and surfaces tests that show inconsistent outcomes on the same SHA. The flakiness page ranks tests by historical instability and shows recent failure traces.
Pricing: Per-repository monthly subscription with a free tier for open source.
Best for: Teams that want flaky test detection without buying into a larger platform. Particularly common at startups and mid-market companies that already have a settled CI stack and just want better visibility into test stability.
Where it falls short: BuildPulse handles detection well, but does not own the quarantine workflow. You see which tests are flaky; what you do with that information lives in your own CI config or merge queue. Teams that want detection plus automatic quarantine integrated into the merge flow end up gluing BuildPulse to a second tool.
Reference: buildpulse.io
3. TestDino
TestDino is an AI-driven test stability platform built around Playwright, with broader framework support added over the past year. The detection layer uses statistical analysis combined with AI-driven root cause categorization that groups recurring failure patterns automatically. The category clustering is the part that stands out: rather than just naming flaky tests, TestDino tries to tell you why each one is unstable.
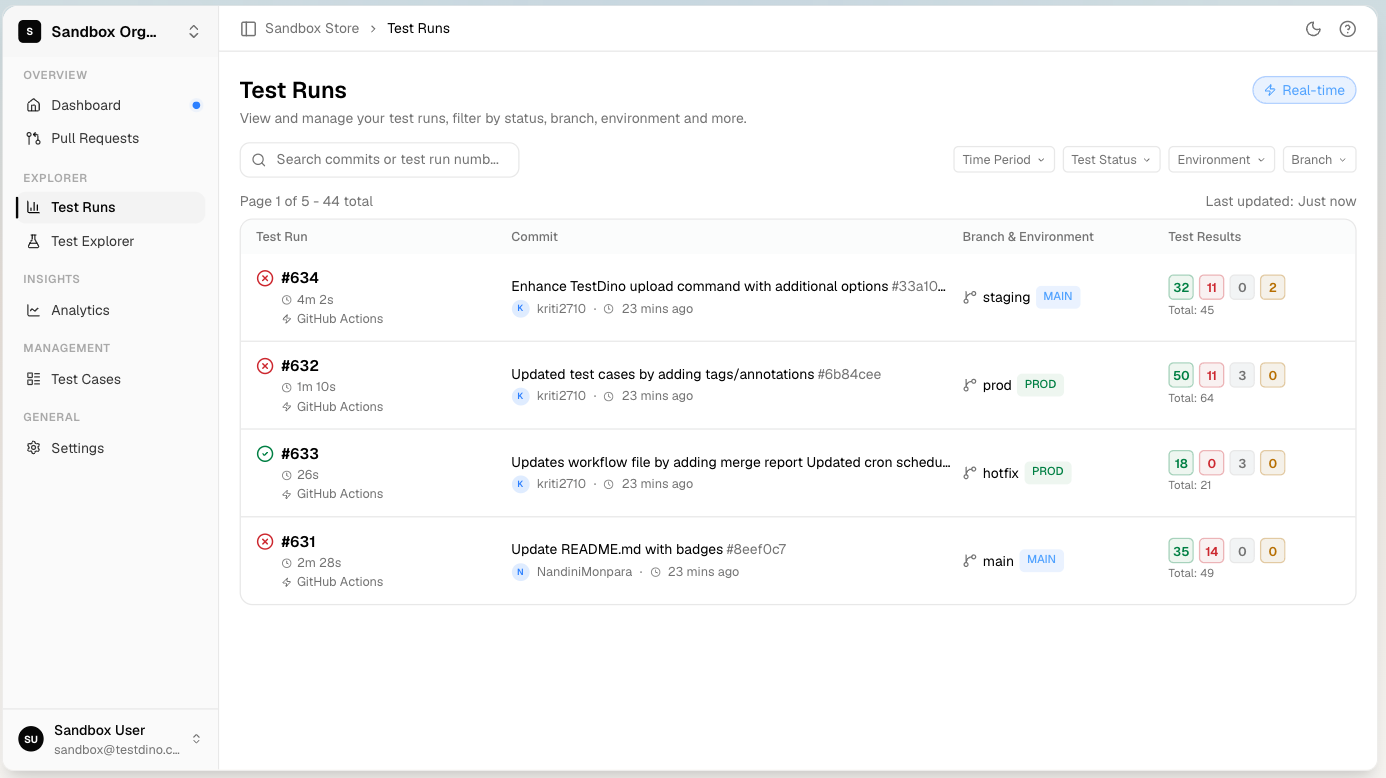
How detection works: TestDino ingests test results from your CI runs and applies machine learning models to group failures by likely root cause (timing, selector instability, environment-dependent assertions, others). The dashboard shows ranked tests with their pattern category and historical pass/fail data per SHA.
Pricing: SaaS with a free tier; paid plans scale with test volume.
Best for: Teams running browser test suites (Playwright, Cypress, Selenium) where root cause analysis matters more than raw detection. The AI categorization is especially useful for QA-led orgs that need to triage flakiness across hundreds of tests.
Where it falls short: Stronger on UI test suites than on backend unit tests. The AI categorization assumes patterns the model has seen, which means unusual flakiness modes can get miscategorized. Smaller company than the platforms in this list, so the long-term roadmap depends on continued investment.
Reference: testdino.com
5. Datadog Test Visibility
Datadog Test Visibility is the test-focused product in Datadog's broader observability platform. It correlates test results with infrastructure metrics, traces, and logs, which makes it useful for teams that already run Datadog for application monitoring and want CI signals in the same place.
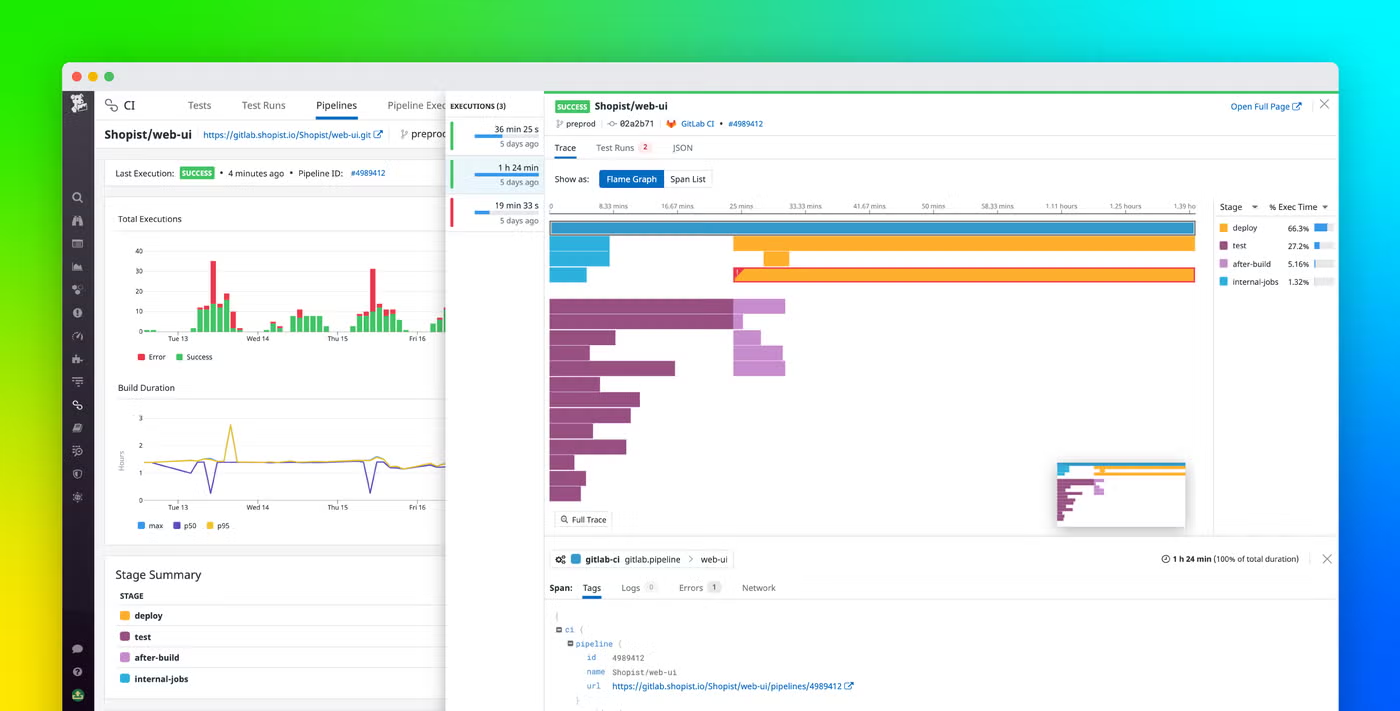
How detection works: Datadog ingests test results via a tracing library or CI plugin. The platform identifies flaky tests by comparing outcomes across runs and exposes them in a dedicated flakiness view. Failures can be cross-referenced against infrastructure events, which is occasionally useful for tracking down environmental causes.
Pricing: Per-million-tests pricing on top of an existing Datadog contract. Expensive at scale, but cost-effective if you already pay for the platform.
Best for: Enterprise teams already running Datadog for application observability. The cross-correlation between test failures and infrastructure events is a real differentiator if you are debugging tests that fail because of upstream service flakiness, not test code itself.
Where it falls short: Heavy onboarding and configuration if you do not already use Datadog. Pricing is opaque and tends to surprise teams the second year. Detection happens in the observability layer, not the merge queue layer, so you still need to wire quarantine into your CI config separately.
Reference: docs.datadoghq.com/tests
6. CircleCI Test Insights
CircleCI Test Insights is built into the CircleCI platform. If you run CircleCI as your CI provider, this is the lowest-friction entry on the list because there is nothing extra to install. The flakiness detection is a tab in the same dashboard your engineers already use.
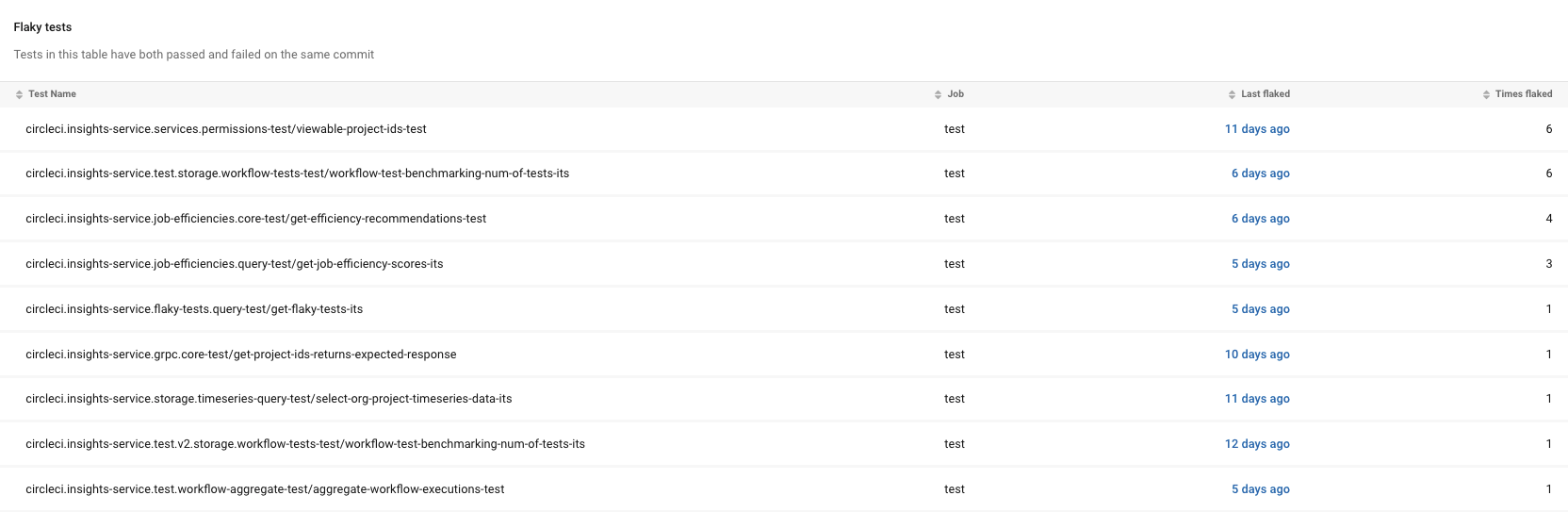
How detection works: CircleCI tracks every test result that runs on the platform and flags inconsistencies automatically. The Test Insights tab shows flaky tests ranked by failure rate, time impact on the pipeline, and history. There is no separate upload step because the platform already has the data.
Pricing: Included in CircleCI's paid plans at no extra cost. Free CircleCI users get a limited view.
Best for: Teams running CircleCI as their primary CI. The zero-install setup is the headline benefit, and the dashboard is integrated with the rest of the build experience your engineers already know.
Where it falls short: Locked to CircleCI. If you run GitHub Actions, Jenkins, or Buildkite for any part of your CI, the data is invisible. No quarantine workflow at the merge queue layer, so the signal mostly serves dashboards and post-hoc investigation rather than changing pipeline behavior in real time.
Reference: circleci.com/test-insights
How to choose
The six tools above split into two real camps. The first is specialty detection tools (BuildPulse, TestDino) which do flaky detection extremely well but stop at the dashboard. The second is integrated platforms (Mergify Test Insights, Datadog Test Visibility, CircleCI Test Insights) which embed detection inside a larger product so the signal can change downstream behavior.
The decision usually comes down to two questions:
What do you want the flakiness signal to actually do? If the answer is "show engineers a dashboard so they can fix the bad tests", a specialty tool is enough. If the answer is "stop flaky tests from blocking the merge queue, automatically", you need an integrated platform that controls more than just detection.
Are you already inside one of these ecosystems? Teams already on Datadog get Test Visibility at a marginal add cost. Teams on CircleCI get a free upgrade with Test Insights. Teams on Mergify get Test Insights bundled. If you are not in any of those ecosystems yet, the specialty tools are a cleaner starting point because they do not lock you in.
A practical sequence we see often: teams start with a specialty tool (BuildPulse, or TestDino) to get visibility into how flaky their suite actually is, then move to an integrated platform once they want the detection signal to drive merge or retry behavior.
Closing thought
Flaky tests are one of those problems where the right tool matters less than the discipline of actually fixing the tests it surfaces. Detection is the easy part. Quarantine is the stopgap. The lasting fix is engineering time spent on the root causes (shared state between tests, race conditions in async code, hardcoded timeouts that break under runner load, test-order dependency under parallel execution). Any of the six tools above will surface what is broken. The one you pick is the one whose workflow your team will actually use.
If you want the integration angle (detection that automatically changes merge queue behavior), Mergify Test Insights is what we built and it ships as part of every Mergify plan. If you want detection-only and a fast start BuildPulse and TestDino are all solid. If you are already on Datadog or CircleCI, their built-in options are the lowest-friction starting point.